
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
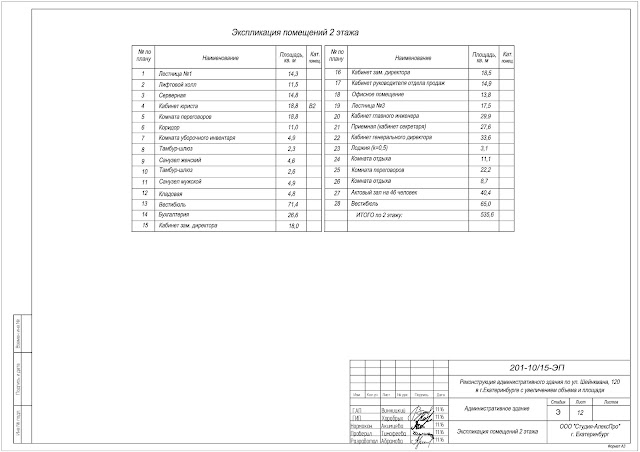
 1.7 Заголовки
1.7 Заголовки Цоколь
Цоколь


 В меню выберите “Середина Между 2 Точками” (“Mid Between 2 Points”) и щелкните две точки диагонали прямоугольника-ячейки.
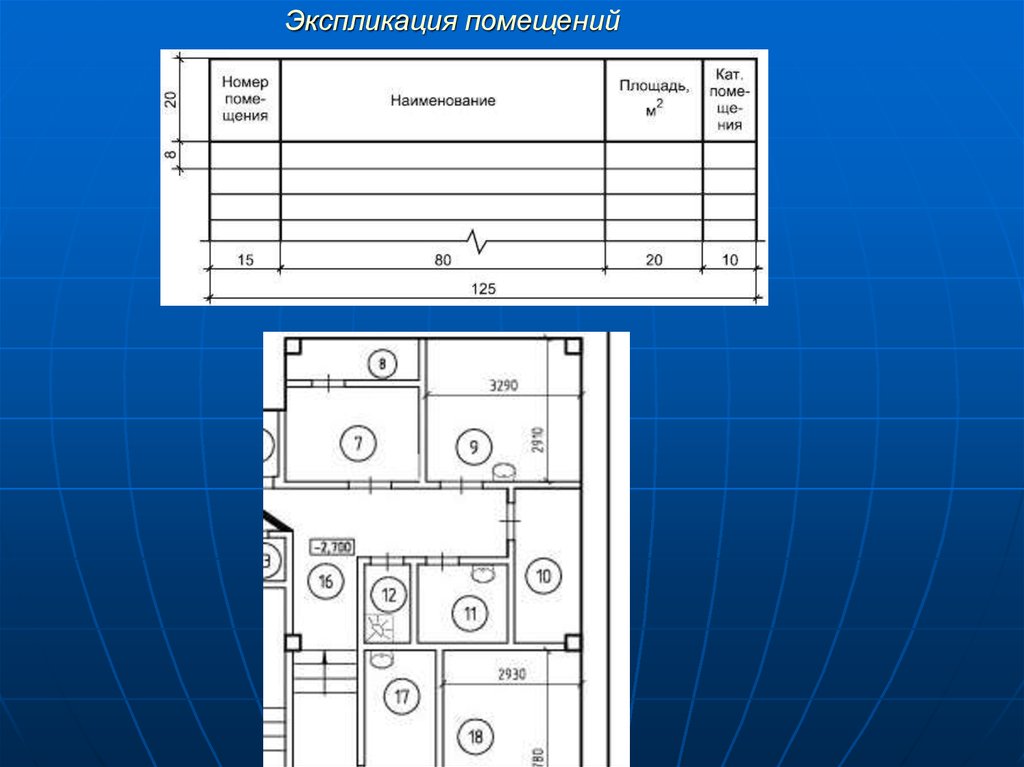
В меню выберите “Середина Между 2 Точками” (“Mid Between 2 Points”) и щелкните две точки диагонали прямоугольника-ячейки.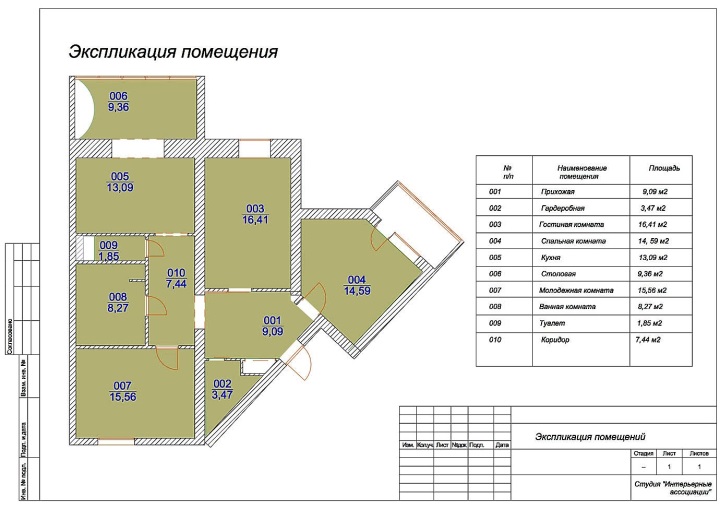 Назовите блок, например, “Explic1”, задайте точку вставки блока (base point) на 20 мм выше ее правого угла (это даст возможность очень красиво и точно помещать экспликацию туда, где она и длжна быть – в правом верхнем углу чертежа, на 20 мм ниже верхней границы формата).
Назовите блок, например, “Explic1”, задайте точку вставки блока (base point) на 20 мм выше ее правого угла (это даст возможность очень красиво и точно помещать экспликацию туда, где она и длжна быть – в правом верхнем углу чертежа, на 20 мм ниже верхней границы формата). Откройте закладку “Заголовок” (“Title”) и уберите все границы заголовка, кроме нижней. Для этого в группе “Свойства границ” (“Border properties”) нажмите последовательно кнопки (“Без границ”, “No Borders”) и (“Нижняя Граница”, “Bottom Border”). Для целей, которые мы сейчас преследуем, этих настроек стиля таблицы вполне достаточно. Закройте все диалоговые окна, нажав “ОК” и “Закрыть” (“Close”).
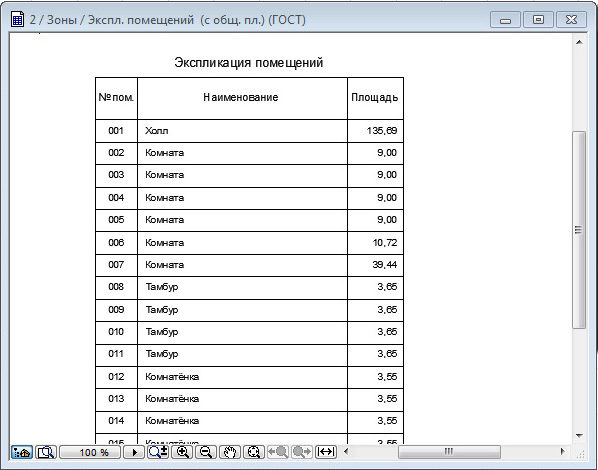
Откройте закладку “Заголовок” (“Title”) и уберите все границы заголовка, кроме нижней. Для этого в группе “Свойства границ” (“Border properties”) нажмите последовательно кнопки (“Без границ”, “No Borders”) и (“Нижняя Граница”, “Bottom Border”). Для целей, которые мы сейчас преследуем, этих настроек стиля таблицы вполне достаточно. Закройте все диалоговые окна, нажав “ОК” и “Закрыть” (“Close”). Не стоит отказываться – смело наберите название – “Экспликация помещений”. Перед этим не забудьте поставить высоту текста (text height) 5 мм (по умолчанию она – 3,5). Нажмите “Enter” – курсор переместится на следующую строчку – левую ячейку шапки таблицы. Заполните шапку так, как заполняли в предыдущем способе (напомню – “Номер пом.”, “Наименование”, “Площадь, м2”, “Кат. пом.” – слева направо).
Не стоит отказываться – смело наберите название – “Экспликация помещений”. Перед этим не забудьте поставить высоту текста (text height) 5 мм (по умолчанию она – 3,5). Нажмите “Enter” – курсор переместится на следующую строчку – левую ячейку шапки таблицы. Заполните шапку так, как заполняли в предыдущем способе (напомню – “Номер пом.”, “Наименование”, “Площадь, м2”, “Кат. пом.” – слева направо). Перейдите к следующей ячейке – “Наименование”, аналогично задайте ее ширину, равной 80 (обратите внимание, что значение высоты распространилось на всю шапку, и ее корректировать нет необходимости – весьма удобно!). Так же поступите с ячейками “Площадь, м2” (ширина 20 мм) и “Кат. пом.” (10 мм). Вам не доставит трудности установка высоты двух оставшихся строк – просто выделите их и установите в свойстве “Ячейка/Высота ячейки” (“Cell/Cell height”) значение “8”.
Перейдите к следующей ячейке – “Наименование”, аналогично задайте ее ширину, равной 80 (обратите внимание, что значение высоты распространилось на всю шапку, и ее корректировать нет необходимости – весьма удобно!). Так же поступите с ячейками “Площадь, м2” (ширина 20 мм) и “Кат. пом.” (10 мм). Вам не доставит трудности установка высоты двух оставшихся строк – просто выделите их и установите в свойстве “Ячейка/Высота ячейки” (“Cell/Cell height”) значение “8”. Назовите ее “Explic2”.
Назовите ее “Explic2”.Добавление таблицы в документ – Служба поддержки Майкрософт
Visio
Форматирование страниц
Страницы
Страницы
Добавление таблицы в документ
Visio Online (план 2) Visio профессиональный 2019 Visio стандартный 2019 Visio профессиональный 2016 Visio стандартный 2016 Visio профессиональный 2013 Visio 2013 Еще. ..Меньше
..Меньше
В документе Visio можно создавать таблицы с помощью фигур, хотя возможности их редактирования ограничены. Если вам нужна настраиваемая таблица или вы хотите отобразить данные, которые могут изменяться, лучше создайте таблицу в Excel, Word или PowerPoint, а затем вставьте ее в документ.
Создание таблицы с помощью фигур Visio
Самые распространенные фигуры Visio для создания таблиц включены в набор элементов Фигуры для диаграмм.
В окне Фигуры нажмите кнопку Дополнительные фигуры и выберите Бизнес > Диаграммы и графики, а затем — Фигуры для диаграмм. В окне Фигуры отобразится набор элементов.
Самую обычную таблицу проще всего создать с помощью фигуры Сетка.
-
Когда вы отпустите фигуру, появится диалоговое окно Данные фигуры, в котором нужно ввести количество строк и столбцов таблицы. Нажмите кнопку OК, и сетка таблицы отобразится в документе.
Совет: Чтобы переместить таблицу, просто перетащите ее, не нажимая. Если вы нажмете таблицу, может выделиться отдельная ячейка сетки, и тогда таблица не переместится. В этом случае щелкните область вне таблицы и попробуйте перетащить ее еще раз.
-
Чтобы увеличить или уменьшить таблицу, перетащите маркеры изменения размера, расположенные по краям фигуры.
-
Если строкам и столбцам необходимо задать определенные заголовки, перетащите фигуры Заголовок строки и Заголовок столбца на страницу документа и разместите их, где нужно. Дважды щелкните фигуры, чтобы ввести данные.
 org/ListItem”>
org/ListItem”>
Перетащите фигуру Сетка из окна Фигуры на страницу документа.

Дважды щелкните любую ячейку, чтобы начать вводить текст. Чтобы прекратить ввод данных в эту ячейку, нажмите клавишу ESC или щелкните другую часть документа.
Примечание: Размер ячейки не изменяется автоматически, если текст в нее не помещается. Если это важное условие, будет проще создать таблицу в Excel или Word. Подробнее об этом см. ниже.
Вставка таблицы из другой программы Office
Возможно, вам будет легче и удобнее создать таблицу в Excel или Word, а затем переместить ее в документ Visio. Используйте команду Специальная вставка, чтобы сохранить исходное форматирование таблицы и получить возможность редактировать ее в дальнейшем в той программе, в которой ее создали.
Используйте команду Специальная вставка, чтобы сохранить исходное форматирование таблицы и получить возможность редактировать ее в дальнейшем в той программе, в которой ее создали.
Примечание: Вы можете вставить таблицу, созданную в PowerPoint, и сохранить ее исходное форматирование, но вам не удастся отредактировать ее позже даже при использовании команды Специальная вставка.
Копирование из электронной таблицы Excel и документа Word осуществляется одинаково. В данном примере мы воспользуемся листом Excel.
-
Выделите таблицу на листе Excel или только ту ее часть, которую требуется перенести в документ. Щелкните правой кнопкой мыши выделенные ячейки и выберите команду Копировать.
-
Для вставки в виде таблицы Excel в диалоговом окне Специальная вставка в списке Как: выберите Лист Microsoft Excel. Дважды щелкните таблицу в документе, чтобы изменить ее. При этом откроется маленький файл Excel, в котором можно внести изменения.
 org/ListItem”>
org/ListItem”>
В документе Visio щелкните правой кнопкой мыши страницу, на которую нужно добавить таблицу, а затем выберите команду Специальная вставка.
Важно: Обязательно используйте команду Специальная вставка. Если вы выберете команду Вставить, то потеряете строки, столбцы и форматирование таблицы.
Если вы щелкните для вставки в качестве листа или документа, но ничего не происходит, проверьте, какая программа создана в этой таблице. Например, при возврате в Excel может быть обнаружено уведомление безопасности, которое запускается, так как в Visio используется макрос для подключения таблицы к Excel. Нажмите кнопку включить макросыи при пополучении другого уведомления о подключениях к данным нажмите кнопку включить. После этого таблица будет отображаться в документе Visio.
Нажмите кнопку включить макросыи при пополучении другого уведомления о подключениях к данным нажмите кнопку включить. После этого таблица будет отображаться в документе Visio.
Совет: Если вы считаете, что таблицу не потребуется редактировать в будущем, в диалоговом окне Специальная вставка в списке Как: выберите вариант Рисунок. При этом таблица сохранит форматирование программы, в которой она была создана.
Гост на экспликацию технологического оборудования — Защитим Законом
⭐ ⭐ ⭐ ⭐ ⭐ Добрый день, читатели моего блога, сейчас будем постигать всем необходимую тему — Гост на экспликацию технологического оборудования. Возможно у Вас могут еще остаться вопросы, после того как Вы прочтете, поэтому лучше всего задать их в комметариях ниже, а еще лучше будет — получить консультацию у практикующих юристов по всем видам права от наших партнеров.
Постоянно обновляем информацию и следим за ее обновлением, поэтому можете быть уверенными, что Вы читаете самую новую редакцию.
3.2. Встроенные помещения и другие участки здания (сооружения), на которые выполняют отдельные чертежи, на планах изображают схематично тонкой штриховой линией в виде перекрещенного контура с показом опорных конструкций.
ГОСТ -80Система проектной документации для строительства
Объем замаркированных на рабочих чертежах основного комплекта марки АР сборных бетонных и железобетонных элементов конструкций включают в ведомость объемов сборных бетонных и железобетонных конструкций в составе рабочих чертежей основного комплекта марки КЖ.
Организации:
все (независимо от размеров) проемы, отверстия, борозды, ниши и гнезда в стенах и перегородках с необходимыми размерами и привязками, за исключением предусмотренных в чертежах изделий или в рабочих чертежах марок КЖ, КМ и КМД. Для проемов с четвертями размеры показывают по наименьшей величине проема. Размеры дверных проемов в перегородках на планах не показывают.
При проектировании и разработке особо опасных, технически сложных и уникальных объектов заказчик совместно с генеральным проектировщиком, научно-исследовательскими и специализированными проектными организациями должен разрабатывать технические условия, отражающие специфику их проектирования, строительства и эксплуатации.
— пояснительную записку, содержащую: выходные проектные данные, основные технико-экономические показатели и характеристики, являющиеся критическими для безопасной и надлежащей эксплуатации; нагрузки и воздействия на металлические конструкции и другие необходимые данные;
5.1 Общие данные
Примечание — При пользовании настоящим стандартом целесообразно проверить действие ссылочных стандартов по указателю «Национальные стандарты», составленному по состоянию на 1 января текущего года, и по соответствующим информационным указателям, опубликованным в текущем году. Если ссылочный стандарт заменен (изменен), то при пользовании настоящим стандартом следует руководствоваться заменяющим (измененным) стандартом. Если ссылочный стандарт отменен без замены, то положение, в котором дана ссылка на него, применяется в части, не затрагивающей эту ссылку.
1.3. Основной комплект рабочих чертежей марки ЭО допускается объединять с основным комплектом рабочих чертежей силового электрического оборудования или с другими основными комплектами электротехнических рабочих чертежей. Объединенному основному комплекту рабочих чертежей присваивается одна марка.
Объединенному основному комплекту рабочих чертежей присваивается одна марка.
Таблица экспликация оборудования гост
С учетом положений ст.87, 88, 136 Федерального закона №123-ФЗ от 22.07.2008 г. степень огнестойкости строительных конструкций производственных зданий и сооружений необходимо принять равной II в соответствии с классом функциональной пожарной опасности — Ф5.1 (здания производственного назначения, в соответствии со ст. 32 Федерального закона №123-ФЗ) и пожарной опасности технологического процесса.
Таблица экспликация оборудования гост
Согласно действующему законодательству, каждый человек должен занимать не мене десяти квадратных метров жилой площади, да еще и иметь долю во вспомогательной. Значит, что квартира, общей площадью, например, шестьдесят квадратных метров вполне может оказаться слишком маленькой даже для четырех человек – в случае, если жилой площади в сумме меньше сорока.
Технологические решения определяют уровень продукции, ее соответствие требуемому уровню и ее качество, т. е. гарантированное соответствие документации, техническому заданию и техническим условиям на продукцию или изделие.
е. гарантированное соответствие документации, техническому заданию и техническим условиям на продукцию или изделие.
Таблица экспликация оборудования гост
Рабочие чертежи внутреннего электрического освещения допускается оформлять отдельными документами с присвоением им базовой марки основного комплекта и добавлением через точку порядкового номера документа, обозначаемого арабскими цифрами, например, общие данные по рабочим чертежам (ЭО1.1), принципиальная схема питающей сети (ЭО1.2).
Приложение Е (справочное) Пример оформления разбивочного плана
Технологические решения определяют уровень продукции, ее соответствие требуемому уровню и ее качество, т.е. гарантированное соответствие документации, техническому заданию и техническим условиям на продукцию или изделие.
На предприятиях, занимающихся выпуском продовольственной продукции, применяют различные машины, которые обеспечивают автоматизированный процесс работы. Установленную автоматику можно классифицировать в инструменты и оборудование при работе с сортовым прокатом по определенным признакам. Это различные группы машин, различающиеся выполняемыми функциями. Все технологические операции можно классифицировать по принципу выполняемой работы, по устройству и методам выполнения.
Установленную автоматику можно классифицировать в инструменты и оборудование при работе с сортовым прокатом по определенным признакам. Это различные группы машин, различающиеся выполняемыми функциями. Все технологические операции можно классифицировать по принципу выполняемой работы, по устройству и методам выполнения.
В любом офисе или на предприятии, с помощью специальных приборов, поддерживается оптимальная температура воздуха, и воздухообмен. Это необходимо для организации комфортного рабочего процесса. Среди разновидностей приборов используют купить оборудование для переработки фруктов.: вытяжки, кондиционеры различных модификаций, вентиляционные шахты с естественным и искусственным охлаждением. Вентиляция бывает вытяжная, приточная и механическая.
Важно: экспликация технологического оборудования гост
На любом предприятии (заводы, фабрики), большое значение имеет грамотная подача воздуха, а так же охлаждение воды, необходимое в любом технологическом процессе. Для этих целей применяют специальные системы, оснащенные вентиляторами. Различные насосы и вентиляторы — это экспликация технологического оборудования гост для стабилизации температурного процесса на производстве. Специальные машины контролируют расход электрической энергии и поглощают шумовой эффект.
Различные насосы и вентиляторы — это экспликация технологического оборудования гост для стабилизации температурного процесса на производстве. Специальные машины контролируют расход электрической энергии и поглощают шумовой эффект.
2.5. На оборудовании и трубопроводах должны быть выполнены предусмотренные конструкторской документацией покрытия свинцом, пластмассой, эмалью, лаками горячего отвердения, гуммированием и т.п., а также подготовлены поверхности, подлежащие торкретированию, футеровке штучными материалами и нанесению антикоррозионного покрытия в проектном положении после монтажа.
1.7. В конструкторской документации на оборудование, подлежащее выверке при монтаже, должны быть указаны выверочные базы, обозначающие места фиксации осей оборудования, а также площадки или поверхности для установки уровней и других накладных средств измерения, предусмотрены при необходимости регулировочные винты.
ГАРАНТ:
1.9. В конструкции оборудования, транспортируемого составными частями, должны быть предусмотрены штифты, болты, планки или другие фиксирующие детали, а также нанесены маркировочные знаки (риски), обеспечивающие повторяемость заводской сборки.
«Создание графических изображений» — Особенности создания векторного изображения в среде Word 2003. Кнопка Автофигуры предназначена для рисования различных геометрических фигур. Задание 4. Создать рисунок, состоящий из автофигур. Полотно. Границы полотна. Задание 2. Вставка картинки из коллекции Microsoft Word. Вставка ? Рисунок ? Картинки.
«Профессиональное оборудование кухни» — Как профессиональная кухня может выглядеть? («De manincor»). Заготовка и хранение продуктов «впрок». Полный спектр услуг. Обслуживание приемов, праздников. Когда к нам обращаться? Наши преимущества: 1. Профессиональное ресторанное оборудование небольших размеров. Присоединительная мощность примерно равна 34 кВт.
Похожие презентации
Изображение технологического оборудования на плане цеха Технологическое оборудование чертят с упрощёнием формы, но в соответствии с масштабом чертежа и нумеруют. Номер пишут на изображении или на полке линии-выноски. Номера оборудования на изображении должны соответствовать порядковым номерам экспликации. Экспликация оборудования (explication – разъяснение) – таблица на чертеже, в которой перечисляется изображённое на чертеже оборудование цеха. Форма и размеры граф экспликации стандартами не установлены. В экспликации обязательно указывается позиция (порядковый номер), наименование и количество каждого вида оборудования. В экспликации может быть указана марка (номер модели) оборудования, другие параметры. В Железногорском горно-металлургическом колледже, как правило, экспликация оборудования оформляется по форме, показанной на рисунке.
Экспликация оборудования (explication – разъяснение) – таблица на чертеже, в которой перечисляется изображённое на чертеже оборудование цеха. Форма и размеры граф экспликации стандартами не установлены. В экспликации обязательно указывается позиция (порядковый номер), наименование и количество каждого вида оборудования. В экспликации может быть указана марка (номер модели) оборудования, другие параметры. В Железногорском горно-металлургическом колледже, как правило, экспликация оборудования оформляется по форме, показанной на рисунке.
Сейчас не только производственное оборудование и установки, но и станки имеют встроенную автоматику, что очень выгодно для производителя и не придется пользоваться услугами сменного оператора. В основном все выполняет техника, при производстве которой используются ноу-хау, экспликация технологического оборудования гост, новейшие разработки и особые «фишки», известные только дизайнерам, инженерам и проектировщикам.
Экспликация технологического оборудования гост
Как и любая техника, заказываемое через каталог специальное оборудование, нуждается в профилактике и ремонте вышедших из строя деталей, узлов или других составляющих механической части или электроники. Поэтому, заказывая необходимые для работы модели через каталог производителя, придется заранее уточнить о возможности поставок необходимых запчастей.
Поэтому, заказывая необходимые для работы модели через каталог производителя, придется заранее уточнить о возможности поставок необходимых запчастей.
Искать экспликация технологического оборудования гост
В выборе необходимого оборудования или станков помогут опытные консультанты, которые прекрасно осведомлены в наличии на складе магазина той или иной модели, а также о ее заводской комплектации и обо всем, что касается оформления заказа, конкретных сроков доставки и расчета точной стоимости общей поставки и монтажа. Поставщики помогут в правильной комплектации спецтехники, при этом грамотно проконсультируют по всем возникшим вопросам, что касаются сборки и монтажа непосредственно на месте поставленного оборудования, станков или автоматизированных комплексов.
12 Апр 2021 uristlaw 372
Поделитесь записью
Работа с таблицами – Полигон Про
Выделение в таблице
Чтобы:
- выделить ячейку – щелкните левой кнопкой мыши по нужной ячейке;
выделить строку – щелкните по номеру строки;
Для выделения нескольких строк, удерживая левую кнопку, перемещайте мышь по столбцу с номерами строк.

выделить столбец – щелкните по заголовку столбца;
- выделить блок ячеек (прямоугольную область) – наведите мышь в один из углов блока, удерживая левую кнопку, перемещайте мышь в противоположный угол блока;
- выделить все ячейки таблицы – щелкните мышью по самому верхнему левому прямоугольнику таблицы – .
Вставка строк
Чтобы вставить строку, поставьте курсор в строку и нажмите на панели инструментов таблицы кнопку:
- , чтобы вставить новую строку над строкой, где стоит курсор;
- , чтобы вставить новую строку под строкой, где стоит курсор.
Существующие строки будут сдвинуты вниз.
Удаление строк
Чтобы удалить строку, установите курсор в строку и нажмите на панели инструментов кнопку .
Перемещение строк
Чтобы переместить строку, поставьте курсор в нужную строку и нажмите на панели инструментов таблицы кнопку:
- , чтобы опустить выделенную строку (строки) ниже;
- , чтобы поднять выделенную строку (строки) выше.
Существующие строки будут сдвинуты.
Изменение размеров таблицы
При загрузке программы размеры таблиц по вертикали минимальны, Вы можете увеличить их высоту, чтобы было видно большее количество строк. Для этого наведите курсор на нижнюю границу таблицы, зажмите левую кнопку мыши и перемещайте курсор вниз, растягивая таблицу:
Чтобы развернуть таблицу на весь экран, на панели инструментов таблицы нажмите кнопку .
Чтобы вернуть таблице нормальный размер, нажмите кнопку .
Ввод данных в таблицы с координатами
Для работы с таблицами с координатами предусмотрено два способа:
- В режиме структуры;
- В режиме таблицы.
Режим структуры открывается по умолчанию.
В данном режиме таблица имеет панель с деревом объектов, доступных для создания. Дерево позволяет создавать, удалять, перемещать объекты.
Добавление объектаЧтобы добавить новый объект в таблицу с координатами, щелкните по типу объекта, например, .
Программа создаст новый узел в дереве и назначит ему имя по умолчанию. Чтобы переименовать объект дважды щелкните по его названию и введите новое:
Некоторые объекты могут быть многоконтурными, например, объект типа “Участок”. Чтобы добавить новый контур, нажмите на . Программа автоматически назначит ему имя по умолчанию:
Внимание!
Если добавляемый объект имеет тип “ЕЗП” (единое землепользование), то вместо контуров будут добавляться входящие участки.
Контур имеет одну внешнюю границу и может содержать несколько внутренних границ (“дырок”). Для добавления внешней границы контура нажмите . Внесите в появившуюся справа таблицу необходимые данные.
Аналогично происходит добавление внутренних границ (“дырок”). Нажмите и внесите необходимые данные.
Удаление объектовЧтобы удалить какой-либо объект из дерева объектов, щелкните по нему и нажмите на панели инструментов кнопку либо клавишу Delete.
Вы можете удалить несколько объектов одновременно, для этого нажмите и удерживайте клавишу Ctrl и левой кнопкой мыши выделите объекты, которые хотите удалить.
Для удаления группы объектов выделите первый объект группы, потом нажмите и удерживайте клавишу Shift, и щелкните по последнему объекту группы.
Над деревом объектов находится панель инструментов для работы с объектами и координатами. Справа находится таблица для описания координат.
Описание панели инструментовПанель инструментов содержит следующие кнопки:
- – развернуть все узлы дерева объектов;
- – свернуть все узлы дерева объектов;
- – пронумеровать контуры всех или только выделенных объектов по порядку;
- – пронумеровать выделенный диапазон точек в таблице координат;
- – определить порядок границ;
- – скопировать координаты из других разделов, которые содержат таблицы с координатами;
- – открывает меню импорта координат в таблицу из текстовых форматов и программы MapInfo:
- – открывает меню экспорта координат из таблицы в текстовые форматы или программу MapInfo:
- – открывает меню с вариантами изменения порядка обхода точек:
- – открывает меню с вариантами конвертации координат точек:
- – разворачивает таблицу в режиме просмотра чертежа;
- – удалить выделенный объект.
В режиме таблицы отсутствует дерево объектов. Вы можете вводить координаты, как в программе “Полигон”: сначала в строке указывается обозначение объекта, затем в следующей строке обозначение контура, далее вносятся координаты объекта.
Что такое таблица фактов? | Определение из TechTarget
Управление даннымиК
- Участник TechTarget
Таблица фактов — это центральная таблица в звездообразной схеме хранилища данных. Таблица фактов хранит количественную информацию для анализа и часто денормализована.
Таблица фактов работает с таблицами измерений. Таблица фактов содержит данные для анализа, а таблица измерений хранит данные о способах анализа данных в таблице фактов. Таким образом, таблица фактов состоит из двух типов столбцов. Столбец внешних ключей позволяет выполнять соединения с таблицами измерений, а столбцы показателей содержат анализируемые данные.
Столбец внешних ключей позволяет выполнять соединения с таблицами измерений, а столбцы показателей содержат анализируемые данные.
Предположим, что компания продает товары клиентам. Каждая продажа — это факт, который происходит, и таблица фактов используется для записи этих фактов. Например:
| Идентификатор времени | Код продукта | Идентификатор клиента | Продано |
| 4 | 17 | 2 | 1 |
| 8 | 21 | 3 | 2 |
| 8 | 4 | 1 | 1 |
Теперь мы можем добавить таблицу измерений о клиентах:
Идентификатор клиента | Имя | Пол | Доход | Образование | Регион |
| 1 | Брайан Эдж | М | 2 | 3 | 4 |
| 2 | Фред Смит | М | 3 | 5 | 1 |
| 3 | Салли Джонс | Ф | 1 | 7 | 3 |
В этом примере столбец идентификатора клиента в таблице фактов является внешним ключом, который соединяется с таблицей измерений. Перейдя по ссылкам, вы можете увидеть, что в строке 2 таблицы фактов записан тот факт, что клиент 3, Салли Джонс, купила два товара в день 8. У компании также будет таблица продуктов и таблица времени, чтобы определить, что купила Салли и именно когда.
Перейдя по ссылкам, вы можете увидеть, что в строке 2 таблицы фактов записан тот факт, что клиент 3, Салли Джонс, купила два товара в день 8. У компании также будет таблица продуктов и таблица времени, чтобы определить, что купила Салли и именно когда.
При построении таблиц фактов существуют физические ограничения и ограничения данных. Следует учитывать конечный размер объекта, а также пути доступа. Добавление индексов может помочь в обоих случаях. Однако с точки зрения логического проектирования ограничений быть не должно. Таблицы должны быть построены на основе текущих и будущих требований, гарантируя максимальную гибкость конструкции, позволяющую вносить будущие улучшения без необходимости перестраивать данные.
Последнее обновление: апрель 2012 г.
Продолжить чтение О таблице фактов- Дизайн таблиц в OLAP и OLTP
- Определение многомерной и нормализованной структуры базы данных, размерности и таблицы фактов
- В чем разница между таблицами фактов и таблицами измерений в звездообразных схемах?
- Рекомендации по дизайну таблицы фактов и размеров
первичный ключ (основное ключевое слово)
Автор: Кинза Ясар
Ключи СУБД: определено 8 типов ключей
Автор: Марк Уайтхорн
осколки
Автор: Рахул Авати
7 методов и концепций моделирования данных для бизнеса
Автор: Рик Шерман
Бизнес-аналитика
- TigerGraph расширяет фундаментальные возможности в последнем обновлении платформы
После недавних обновлений, посвященных языкам запросов и машинному обучению, новейшее обновление поставщика графовой базы данных .
.. - Qlik создаст множество коннекторов для пакета интеграции данных
Поставщик представил Connector Factory, стратегию создания сотен новых соединителей для своей платформы iPaaS, позволяющую пользователям …
- Informatica добавляет бесплатный инструмент интеграции данных без кода
В рамках стремления сделать управление данными доступным не только специалистам по данным, поставщик предлагает новые бесплатные и …
 ..
..ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Сервис автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных. Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу.
.. - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи AWS сталкиваются с выбором при развертывании Kubernetes: запускать его самостоятельно на EC2 или позволить Amazon выполнять тяжелую работу с помощью EKS. См…
 ..
..Управление контентом
- Изучите основы управления цифровыми активами
Системы
DAM предлагают центральный репозиторий мультимедийных ресурсов и улучшают сотрудничество в маркетинговых командах. Однако пользователи могут…
- Введение в SharePoint Syntex
SharePoint Syntex — это попытка Microsoft выйти на все более популярный рынок контентных сервисов искусственного интеллекта. Это введение исследует …
- Как перейти на систему управления медиаактивами
Что такое управление медиаактивами и чем оно может помочь вашей организации? Это похоже на управление цифровыми активами, но оно нацелено на .
..
 ..
..ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь в …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, в связи с чем …
ПоискSAP
- Pandora приступает к цифровой трансформации SAP S/4HANA Cloud
Когда ее система ERP устарела, Pandora выбрала S/4HANA Cloud для преобразования своих бизнес-процессов.
Новая система … - Florida Crystals упрощает среду SAP за счет перехода на AWS
Объединение Florida Crystals ландшафта SAP с развертыванием управляемых сервисов SaaS на AWS позволило компании …
- Инструмент Process Mining предоставляет рекомендации на основе прошлых проектов
SAP Signavio Process Explorer — это следующий шаг в развитии интеллектуального анализа процессов, предоставляющий рекомендации по преобразованию …
 Новая система …
Новая система …Константы контрольной диаграммы | Таблицы и краткое пояснение
Перейти к контрольной таблице Константы:
- Константы коррекции смещения: d2, c4, d3, d4
- Константы XmR (n=2): d2, A2, D3, D4
- Константы XbarR: d2, d3, A2, D3, D4
- Константы XbarS: c4, A3, B3, B4
Константы контрольной диаграммы лежат в основе таких диаграмм, как XmR, XbarR и XbarS. И, если вы делали контрольную диаграмму вручную или сидели в классе, вы, вероятно, помните причудливые константы, такие как d2, A2 и т. д. Для меня константы контрольной диаграммы — необходимое зло. Почему? Потому что искать константу для построения диаграммы неудобно, и я подозреваю, что за эти годы это, вероятно, отпугнуло многих потенциальных пользователей. Однако в наши дни, если у вас есть хорошее статистическое программное обеспечение, вы даже не увидите эти цифры. Варианты с открытым исходным кодом включают пакет R ggQC. Пример графика показан ниже. Другие варианты с открытым исходным кодом включают qcc, iqcc и qicharts, и это лишь некоторые из них.
д. Для меня константы контрольной диаграммы — необходимое зло. Почему? Потому что искать константу для построения диаграммы неудобно, и я подозреваю, что за эти годы это, вероятно, отпугнуло многих потенциальных пользователей. Однако в наши дни, если у вас есть хорошее статистическое программное обеспечение, вы даже не увидите эти цифры. Варианты с открытым исходным кодом включают пакет R ggQC. Пример графика показан ниже. Другие варианты с открытым исходным кодом включают qcc, iqcc и qicharts, и это лишь некоторые из них.
Существуют также коммерчески доступные варианты, такие как minitab или JMP. Независимо от доступного программного обеспечения, все же хорошо иметь место, где можно найти эти числа, когда они вам понадобятся, и быстрое объяснение их использования. Также приятно иметь представление о том, что эти числа означают физически. Для этого ознакомьтесь с моими статьями:
- Оценка констант контрольной диаграммы
- График XmR | Пошаговое руководство вручную и с R
В следующих нескольких разделах вы вкратце увидите, как мы преобразуем такие величины, как средний скользящий диапазон (mR), средний диапазон и среднее стандартное отклонение, в дисперсионную статистику, используя константы контрольной диаграммы.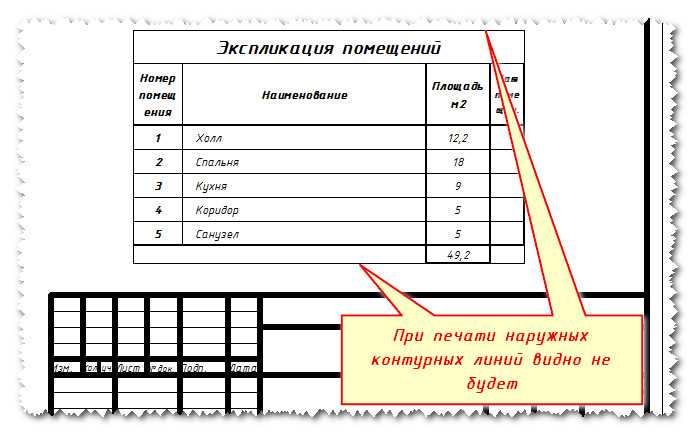 Имея в руках эту дисперсионную статистику, мы можем рассчитать контрольные пределы для наших данных. Для начала мы начнем со строительных блоков — поправочных коэффициентов смещения.
Имея в руках эту дисперсионную статистику, мы можем рассчитать контрольные пределы для наших данных. Для начала мы начнем со строительных блоков — поправочных коэффициентов смещения.
Константы таблицы управления коррекцией смещения
Константы коррекции смещения являются фундаментальными величинами, которые позволяют вам вычислять другие управляющие константы более высокого уровня , такие как A2, D3, D4 и т. д. В последующих разделах приведены примеры расчета этих констант.
Чтобы лучше понять, что представляют собой поправочные коэффициенты смещения, см. мою статью об оценке констант контрольной диаграммы. Там я проведу вас через математику и симуляцию, чтобы собрать все воедино.
Константы коррекции смещения
| n | д2 | с4 | д3 | д4 |
|---|---|---|---|---|
| 2 | 1.1284 | 0,7979 | 0,8525 | 0,9539 |
| 3 | 1,6926 | 0,8862 | 0,8884 | 1,5878 |
| 4 | 2,0588 | 0,9213 | 0,8798 | 1,9783 |
| 5 | 2,3259 | 0,9400 | 0,8641 | 2,2569 |
| 6 | 2,5344 | 0,9515 | 0,8480 | 2,4717 |
| 7 | 2,7044 | 0,9594 | 0,8332 | 2,6455 |
| 8 | 2,8472 | 0,9650 | 0,8198 | 2,7908 |
| 9 | 2,9700 | 0,9693 | 0,8078 | 2,9154 |
| 10 | 3,0775 | 0,9727 | 0,7971 | 3. 0242 0242 |
| 11 | 3,1729 | 0,9754 | 0,7873 | 3.1205 |
| 12 | 3,2585 | 0,9776 | 0,7785 | 3,2069 |
| 13 | 3,3360 | 0,9794 | 0,7704 | 3,2849 |
| 14 | 3,4068 | 0,9810 | 0,7630 | 3,3562 |
| 15 | 3,4718 | 0,9823 | 0,7562 | 3.4217 |
| 16 | 3,5320 | 0,9835 | 0,7499 | 3.4821 |
| 17 | 3,5879 | 0,9845 | 0,7441 | 3,5383 |
| 18 | 3.6401 | 0,9854 | 0,7386 | 3,5907 |
| 19 | 3,6890 | 0,9862 | 0,7335 | 3,6398 |
| 20 | 3,7349 | 0,9869 | 0,7287 | 3,6859 |
| 21 | 3,7783 | 0,9876 | 0,7242 | 3,7294 |
| 22 | 3,8194 | 0,9882 | 0,7199 | 3,7706 |
| 23 | 3,8583 | 0,9887 | 0,7159 | 3,8096 |
| 24 | 3,8953 | 0,9892 | 0,7121 | 3,8468 |
| 25 | 3,9306 | 0,9896 | 0,7084 | 3,8822 |
| 26 | 3,9643 | 0,9901 | 0,7050 | 3,9159 |
| 27 | 3,9965 | 0,9904 | 0,7017 | 3,9482 |
| 28 | 4. 0274 0274 | 0,9908 | 0,6986 | 3,9791 |
| 29 | 4.0570 | 0,9911 | 0,6955 | 4.0088 |
| 30 | 4.0855 | 0,9914 | 0,6927 | 4.0374 |
Константы контрольной диаграммы XmR
Диаграммы XmR — это самые простые в изготовлении контрольные диаграммы. Полное объяснение см. в следующих статьях:
- XmR Chart | Пошаговое руководство вручную и с R
- Как сделать диаграммы XmR с помощью ggQC
Константы XmR
| n | д2 | д3 | Д4 |
|---|---|---|---|
| 2 | 1.1284 | 0,8525 | 3,2665 |
Справочник по расчету диаграммы XmR
- Найдите центральную линию, вычислив среднее значение ваших точек данных
X = среднее (данные) - Определите средний диапазон перемещения ваших точек данных. Данные должны быть в той последовательности, в которой были получены образцы.
мР = среднее (мР) - Преобразование среднего значения (мР) в последовательное отклонение (Š):
Š = мР/ d2 = мР / 1,128 - Расчет верхнего и нижнего контрольных пределов XmR с использованием последовательного отклонения
- Нижний контрольный предел XmR (LCL):
LCL X = X – 3 ⋅ Š - Верхний контрольный предел XmR (UCL):
UCL X = X + 3 ⋅ Š
 Данные должны быть в той последовательности, в которой были получены образцы.
Данные должны быть в той последовательности, в которой были получены образцы. Расчет диаграммы мР
- Найдите центральную линию, рассчитав средний диапазон движения точек данных. Данные должны быть в той последовательности, в которой были получены образцы.
мР = среднее (мР) - Рассчитать верхний и нижний контрольные пределы mR
- мР Нижний контрольный предел:
LCL мР = 0 - мР Верхний контрольный предел:
UCL мР = 1 + 3(d3 / d2) ⋅ мР = D4 ⋅ мР
Дополнительная информация о константе XmR
- Постоянная 2,66 иногда используется для расчета пределов диаграммы XmR. Константа учитывает 3, используемые для расчета верхнего и нижнего контрольного предела.
2,66 = 3 / d2 = 3 / 1,12838 - Используя константу 2,66
Контрольные пределы = X ± 2,66 ⋅ мР - Константа D4 является функцией d2 и d3:
D4 = 1 + 3(d3 / d2) = 3,2665
 Константа учитывает 3, используемые для расчета верхнего и нижнего контрольного предела.
Константа учитывает 3, используемые для расчета верхнего и нижнего контрольного предела. Константы контрольной диаграммы XbarR
Диаграммы XbarR полезны при наличии подгрупп. Например:
- У вас есть очень точный процесс приготовления кексов, в котором используется сковорода, на которой можно приготовить 12 кексов за раз. После приготовления вы измеряете вес каждого кекса, чтобы убедиться, что тесто распределилось равномерно. Здесь размер подгруппы = 12
- У вас есть процесс измерения, при котором вы ежедневно выполняете 5 измерений эталонного стандарта. Здесь размер подгруппы = 5
Чтобы узнать, как создавать диаграммы XbarR с помощью ggQC, ознакомьтесь с примерами на сайте rcontrolcharts.com
Константы XbarR
| n | д2 | д3 | А2 | Д3 | Д4 |
|---|---|---|---|---|---|
| 2 | 1.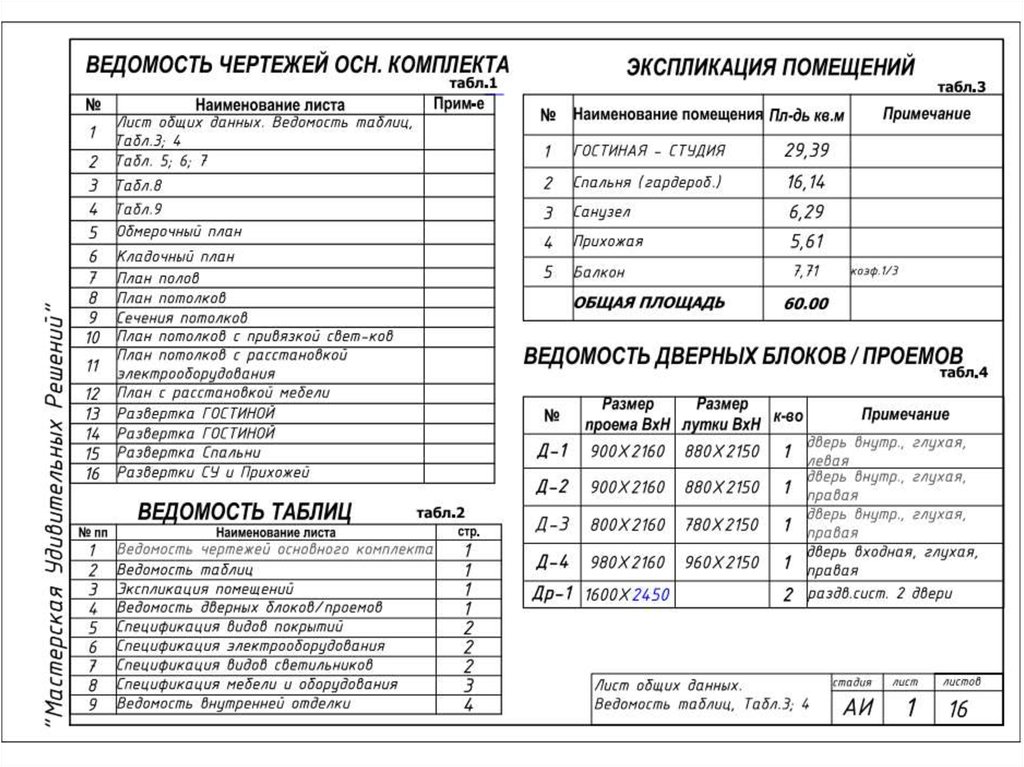 1284 1284 | 0,8525 | 1.8800 | 0,0000 | 3,2665 |
| 3 | 1,6926 | 0,8884 | 1.0233 | 0,0000 | 2,5746 |
| 4 | 2,0588 | 0,8798 | 0,7286 | 0,0000 | 2,2821 |
| 5 | 2,3259 | 0,8641 | 0,5768 | 0,0000 | 2,1145 |
| 6 | 2,5344 | 0,8480 | 0,4832 | 0,0000 | 2,0038 |
| 7 | 2,7044 | 0,8332 | 0,4193 | 0,0757 | 1,9243 |
| 8 | 2,8472 | 0,8198 | 0,3725 | 0,1362 | 1,8638 |
| 9 | 2,9700 | 0,8078 | 0,3367 | 0,1840 | 1,8160 |
| 10 | 3,0775 | 0,7971 | 0,3083 | 0,2230 | 1,7770 |
| 11 | 3,1729 | 0,7873 | 0,2851 | 0,2556 | 1,7444 |
| 12 | 3,2585 | 0,7785 | 0,2658 | 0,2833 | 1,7167 |
| 13 | 3,3360 | 0,7704 | 0,2494 | 0,3072 | 1,6928 |
| 14 | 3,4068 | 0,7630 | 0,2354 | 0,3281 | 1,6719 |
| 15 | 3,4718 | 0,7562 | 0,2231 | 0,3466 | 1,6534 |
| 16 | 3. 5320 5320 | 0,7499 | 0,2123 | 0,3630 | 1,6370 |
| 17 | 3,5879 | 0,7441 | 0,2028 | 0,3779 | 1,6221 |
| 18 | 3.6401 | 0,7386 | 0,1943 | 0,3913 | 1,6087 |
| 19 | 3,6890 | 0,7335 | 0,1866 | 0,4035 | 1,5965 |
| 20 | 3,7349 | 0,7287 | 0,1796 | 0,4147 | 1,5853 |
| 21 | 3,7783 | 0,7242 | 0,1733 | 0,4250 | 1,5750 |
| 22 | 3,8194 | 0,7199 | 0,1675 | 0,4345 | 1,5655 |
| 23 | 3,8583 | 0,7159 | 0,1621 | 0,4434 | 1,5566 |
| 24 | 3,8953 | 0,7121 | 0,1572 | 0,4516 | 1,5484 |
| 25 | 3,9306 | 0,7084 | 0,1526 | 0,4593 | 1. 5407 5407 |
| 26 | 3,9643 | 0,7050 | 0,1484 | 0,4665 | 1,5335 |
| 27 | 3,9965 | 0,7017 | 0,1445 | 0,4733 | 1,5267 |
| 28 | 4.0274 | 0,6986 | 0,1408 | 0,4797 | 1.5203 |
| 29 | 4.0570 | 0,6955 | 0,1373 | 0,4857 | 1,5143 |
| 30 | 4.0855 | 0,6927 | 0,1341 | 0,4914 | 1,5086 |
Справочник по расчету диаграммы XbarR
- Определение размера подгруппы:
n - Рассчитать среднее значение каждой подгруппы:
X = среднее значение (каждой подгруппы) - Найдите центральную линию, вычислив среднее значение всех средних подгрупп:
X̿ = среднее (среднее (каждая подгруппа)) - Определить диапазон Max(value)-Min(Value) для каждой подгруппы:
R = диапазон(каждая подгруппа) - Вычислить средний диапазон диапазонов всех подгрупп:
R = среднее (диапазон (каждая подгруппа)) - Преобразование среднего значения среднего диапазона в пределах отклонения, W d :
W d = R / d2 n - Пример 1: Если n = 3, то W d = R / 1,693
- Пример 2: Если n = 10, то W д = Р/3,078
- Определите верхний и нижний контрольные пределы: естественный или студенческий
- Natural Control Limits предоставит вам окно для отдельных измерений в вашем процессе.
- Нижний предел естественного контроля XbarR:
LNCL x = X̿ – (3 ⋅ W d ) / √ 1 - Верхний предел естественного контроля XbarR:
UNCL x = X̿ + (3 ⋅ W d ) / √ 1
Примечание. Естественные пределы используют √ 1 , а студенческие пределы используют √ n (см. ниже). Это похоже на разницу между стандартным отклонением (SD) и стандартной ошибкой (SD / √ n )
. - Нижний предел естественного контроля XbarR:
- Стьюдентизированные контрольные пределы (метод 1) откроет окно для средних значений подгрупп.
- Нижний предел студенческого контроля XbarR:
LCL x = X̿ – (3 ⋅ W d ) / √ n - Верхний предел студенческого контроля XbarR:
UCL x = X̿ + (3 ⋅ W d ) / √ n
- Нижний предел студенческого контроля XbarR:
- Стьюдентизированные контрольные пределы (метод 2) предоставит вам окно для средних значений подгруппы с использованием контрольной константы A2.
- A2 n = 3 / (d2 n ⋅ √ n )
- Нижний предел студенческого контроля XbarR:
LCL x = X̿ – R ⋅ A2 n - Верхний предел студенческого контроля XbarR:
UCL x = X̿ + R ⋅ A2 n
Быстрая демонстрация : Покажем, что методы 1 и 2 для расчета контрольных пределов дают одинаковый результат.
Предположим, n = 3; X̿ = 5, R = 7,
Метод 1:
для n = 3, D2 = 1,6926, W D = 7 / 1,6926 = 4,1356
LCL x = 5 -3 ⋅ 4.1356 / √ 3 = -2,163
222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222 2990 = 40799990 = 5 -3 -3,1356 / √ 3 = -2,163
2 790 = 5 4. + 3 ⋅ 4,1356 / √ 3 = 12,163
Метод 2:
Для n = 3, A2 = 1,0233,
LCL x = 5 – 7 ⋅ 1,0233 = -2,163
Точка:
Для данного размера подгруппы = n:
A2 n = 3 / (d2 n ⋅ √ n )
R Chart Расчеты
- Определение размера подгруппы:
n - Вычислить диапазон, Макс(значение)-Мин(Значение), для каждой подгруппы:
R = диапазон (каждая подгруппа) - Определите центральную линию, рассчитав средний диапазон всех диапазонов подгрупп:
R = среднее (диапазон (каждая подгруппа)) - Найти пределы управления диаграммой R:
- Ч Нижний контрольный предел:
LCL Ч = D3 ⋅ R - R Верхний контрольный предел:
UCL R = D4 ⋅ R
Дополнительная информация о константах диаграммы R
- Константа D3 является функцией d2, d3 и n.
Если n = 5, то
D3 n=5 = 1 – 3(d3 n=5 / d2 n=5 3 – 0 4 4) = - Константа D4 является функцией d2, d3 и n.
Если n = 5 Тогда
D4 n=5 = 1 + 3(d3 n=5 / d2 n=521 ) 3 = 5 2
2 0 4 = 5 2
) 4 Константы контрольной диаграммы XbarS
Диаграммы XbarS вступают в игру, когда у вас есть подгруппы. Например:
- У вас есть очень точный процесс приготовления кексов, в котором используется сковорода, на которой можно приготовить 12 кексов за раз. После приготовления вы измеряете вес каждого кекса, чтобы убедиться, что тесто распределилось равномерно. Здесь размер подгруппы = 12
- У вас есть процесс измерения, при котором вы ежедневно выполняете 5 измерений эталонного стандарта. Здесь размер подгруппы = 5
Диаграммы XbarS можно создавать с помощью ggQC, используя метод = «xBar.
sBar». Подробнее см. функцию stat_QC().Константы XbarS
n с4 А3 В3 В4 2 0,7979 2,6587 0,0000 3,2665 3 0,8862 1,9544 0,0000 2,5682 4 0,9213 1,6281 0,0000 2,2660 5 0,9400 1.4273 0,0000 2.0890 6 0,9515 1.2871 0,0304 1,9696 7 0,9594 1.1819 0,1177 1,8823 8 0,9650 1.0991 0,1851 1.8149 9 0,9693 1.0317 0,2391 1,7609 10 0,9727 0,9754 0,2837 1,7163 11 0,9754 0,9274 0,3213 1,6787 12 0,9776 0,8859 0,3535 1,6465 13 0,9794 0,8495 0,3816 1,6184 14 0,9810 0,8173 0,4062 1,5938 15 0,9823 0,7885 0,4282 1,5718 16 0,9835 0,7626 0,4479 1,5521 17 0,9845 0,7391 0,4657 1,5343 18 0,9854 0,7176 0,4818 1,5182 19 0,9862 0,6979 0,4966 1,5034 20 0,9869 0,6797 0,5102 1. 489821 0,9876 0,6629 0,5228 1,4772 22 0,9882 0,6473 0,5344 1,4656 23 0,9887 0,6327 0,5452 1,4548 24 0,9892 0,6191 0,5553 1.4447 25 0,9896 0,6063 0,5648 1.4352 26 0,9901 0,5943 0,5737 1.4263 27 0,9904 0,5829 0,5820 1.4180 28 0,9908 0,5722 0,5899 1.4101 29 0,9911 0,5621 0,5974 1.4026 30 0,9914 0,5525 0,6044 1,3956 Справочник по расчету диаграммы XbarS
- Определение размера подгруппы:
n - Рассчитать среднее значение каждой подгруппы:
X = среднее значение (каждой подгруппы) - Найдите центральную линию, вычислив среднее значение всех средних значений подгруппы:
X̿ = среднее (среднее (каждая подгруппа)) - Определите стандартное отклонение для каждой подгруппы:
S = sd (каждая подгруппа) - Рассчитать среднее стандартных отклонений для всех подгрупп:
S = среднее (sd(каждая подгруппа)) - Преобразование среднего стандартного отклонения подгруппы в отклонение в пределах, W d :
W d = S / c4 n - Пример 1: Если n = 3, то W d = S / 0,8862
- Пример 2: Если n = 10, то W d = S / 0,9727
- Определите верхний и нижний контрольные пределы: естественный или студенческий
- Natural Control Limits предоставит вам окно для отдельных измерений в вашем процессе.
- Нижний предел естественного контроля XbarS:
LNCL x = X̿ – (3 ⋅ W d ) / √ 1 - Верхний предел естественного контроля XbarS:
UNCL x = X̿ + (3 ⋅ W d ) / √ 1
Примечание. Естественные пределы используют √ 1 , а студенческие пределы используют √ n (см. ниже). Это похоже на разницу между стандартным отклонением (SD) и стандартной ошибкой (SD / √ n )
. - Нижний предел естественного контроля XbarS:
- Стьюдентизированные контрольные пределы (метод 1) откроет окно для средних значений подгрупп.
- Нижний студенческий контрольный предел XbarS:
LCL x = X̿ – (3 ⋅ W d ) / √ n - Верхний студенческий контрольный предел XbarS:
UCL x = X̿ + (3 ⋅ W d ) / √ n
- Нижний студенческий контрольный предел XbarS:
- Стьюдентизированные контрольные пределы (метод 2) предоставит вам окно для средних значений подгруппы с использованием контрольной константы A3.
- A3 n = 3 / (c4 n ⋅ √ n )
- Нижний предел студенческого контроля XbarS:
LCL x = X̿ – S ⋅ A3 n - Верхний предел студенческого контроля XbarS:
UCL x = X̿ + S ⋅ A3 n
Быстрая демонстрация : Покажем, что методы 1 и 2 для расчета контрольных пределов дают одинаковый результат.
Предположим, n = 3; X̿ = 5, S = 2,
Метод 1:
Для n = 3, c4 = 0,8862, W d = 2 / 0,8862 = 2,25681
UCL x = 5 + 3 ⋅ 2,2568 / √ 3 = 8,909Метод 2:
Для n = 3, A3 = 1,954,
LCL x = 5 – 2 ⋅ 1,0233 = 1,092Точка:
Для данного размера подгруппы = n:
A3 n = 3 / (c4 n ⋅ √ n )S Chart Расчеты
- Определение размера подгруппы:
n - Определите стандартное отклонение для каждой подгруппы:
S = sd (каждая подгруппа) - Рассчитать среднее стандартных отклонений для всех подгрупп:
S = среднее (sd(каждая подгруппа)) - Найти контрольные пределы диаграммы S:
- S Нижний контрольный предел:
LCL S = B3 ⋅ S - S Верхний контрольный предел:
UCL S = B4 ⋅ S
Дополнительная информация о постоянной S-диаграмме
- Константа B3 является функцией c4 и n.
Если n = 5, то
B3 n=5 = 1 – 3 / c4 n=5 ⋅ (√ 1 – (c4)² ) = -0,0889 → 0 - Константа B4 является функцией c4 и n.
Если n = 5, то
B4 n=5 = 1 + 3 / c4 n=5 ⋅ (√ 1 – (c4)² ) = 2,0889
Резюме
Представлены таблицы констант контрольной карты и краткое объяснение того, как константы контрольной карты используются в различных контекстах. Контрольные карты типа XmR, XbarR, XbarS, mR, R и S требуют наличия этих констант для правильного определения контрольных пределов. Для карт XmR требуется только одна константа, необходимая для определения контрольных пределов для отдельных наблюдений, 1,128. Однако для диаграмм XbarR и XbarS константа управления изменяется в зависимости от размера подгруппы. Кроме того, когда вы вычисляете пределы для диаграмм XbarR или XbarS, вам необходимо знать, вычисляете ли вы естественные контрольные пределы для отдельных измерений или студенческие контрольные пределы для средних подгрупп.
Если вы выполняете расчеты вручную, используйте метод 1, описанный выше, чтобы помочь сохранить разницу между индивидуальным и студенческим.Анализ основных данных | Руководство по исследованию рынка
После того, как данные очищены, приведены в порядок и (при необходимости) взвешены, необходимо создать таблицы, интерпретировать их и превратить в отчеты. Он состоит из следующих шагов, но их можно выполнять в любом порядке: сводные таблицы, перекрестные таблицы, проверка значимости и фильтрация данных.
Сводный отчет — это набор таблиц или диаграмм, в которых показана сводная статистика, например средние значения и доля людей в каждой категории, для:
- Все вопросы в опросе.
- Все административные записи, хранящиеся как переменные в файле данных (например, время начала интервью, время, которое потребовалось для завершения интервью, уникальный идентификатор каждого респондента).
Примеры
Основная информация, отображаемая в сводных таблицах в большинстве программ, в основном одинакова, за исключением форматирования.
Следующие два примера взяты из программ, которые настолько непохожи, насколько это вообще возможно: традиционная сводная таблица — это тип, обычно используемый профессиональными исследователями рынка. Во втором примере показан стиль резюме, разработанный для менее опытных исследователей.Displayr
Следующий экран показан из Displayr. Для каждой сводной таблицы (или, при желании, диаграммы) создается отдельная страница. Все таблицы перечислены в левой части экрана. Текстовое поле выделяет некоторые из ключевых особенностей таблицы. Стрелки и цвета используются для выделения результатов, которые значительно выше или ниже.
MarketSight
В сводке, разработанной MarketSight, перечислены все переменные и вопросы, один за другим, в большой таблице. Основные статистические данные, показанные в таблице — проценты и размер выборки — такие же, как показано выше. Кроме того, количество отображается на каждом столе автоматически.
Интерпретация сводного отчета
Категориальные и числовые переменные
Как правило, сводные отчеты содержат таблицы процентных значений для категорийных переменных, таких как возраст и пол, а также таблицы со средними значениями для числовых переменных.
Например, в сводном отчете MarketSight ниже мы видим, что первая таблица показывает среднее значение числовой переменной, а вторая показывает проценты и подсчеты от категориальной переменной.Переключение между категориальными и числовыми переменными
В большинстве программ необходимо изменить метаданные для переключения между средним значением и процентами. Исключениями являются:
- В SPSS пользователь указывает, следует ли запускать среднее значение или частоту вручную для каждой таблицы.
- В Q и Displayr вы можете изменить метаданные или, если они показывают проценты, вы можете использовать Статистика — ниже или Статистика — справа , чтобы добавить средние значения в таблицу процентов.
Вопросы с несколькими ответами
Для вопросов с несколькими ответами существует несколько различных способов вычисления процентов:
- Процент респондентов. Столбец % в приведенной ниже таблице (который был рассчитан с использованием Q) показывает долю респондентов, выбравших ответ (например, 24% для AAPT рассчитывается путем деления 122 человек, выбравших этот вариант, на 498 человек). которым была показана альтернатива (которой в данном случае была вся выборка. Как правило, именно этот процент используется при представлении данных по вопросам с несколькими ответами).
- Процент ответов. Значение % ответов , равное 6 %, вычисляется путем деления 122 на сумму всех подсчетов (т. е. 122/(122 + 46 + … + 401)). Этот процент редко используется и, возможно, никогда не будет полезен, кроме как в качестве исходных данных для очистки данных.
Сводные таблицы множественных ответов с беспорядочными данными
Когда данные опроса «чистые», все основные программы анализа данных, используемые для анализа опросов, дают в основном одинаковые результаты. Однако есть несколько ситуаций, когда программы могут давать совершенно разные результаты.
Пропущенные значения
Когда данные множественных ответов содержат пропущенные значения, программы выдают совершенно разные результаты. Пожалуйста, ознакомьтесь с подсчетом значений и пропущенными значениями в вопросах с несколькими ответами, чтобы узнать, чем отличаются программы, и получить инструкции, как заставить программы давать более разумные результаты.
Когда не все относятся к какой-либо категории
В «аккуратном» опросе каждый должен получить ответ в вопросе с несколькими ответами (т. е. людям не разрешается переходить к следующему вопросу, не выбрав хотя бы один из вариантов ). Однако есть несколько сценариев, когда не у всех будет ответ:
- При наличии проблем с целостностью данных.
- Когда людей не заставляли выбирать вариант.
- Когда вопрос с множественными ответами был создан пользователем (например, при создании двух верхних баллов).
В каждой из этих ситуаций разные программы дают разные результаты. Две приведенные ниже таблицы рассчитаны с использованием данных, где каждый в данных выбрал хотя бы одну категорию. И, как и в случае со всеми стандартными программами, результаты будут одинаковыми. То есть проценты в таблице слева, рассчитанные с помощью Q, такие же (с округлением столбцов), как проценты в правой части второй таблицы, рассчитанные с помощью SPSS. Единственное существенное различие между этими таблицами относится к нижней строке, где Q показывает NET, то есть долю людей, выбравших один или несколько вариантов, тогда как SPSS показывает общее количество.
Две приведенные ниже таблицы также рассчитаны с использованием Q и SPSS. Кроме того, они используют те же данные, что и в приведенных выше таблицах, за исключением того, что в анализ включены только первые четыре категории. Обратите внимание, что Q-анализ почти такой же. Проценты для каждой марки остаются прежними. Единственная разница касается чистой прибыли, которая составляет 100 % для приведенной выше таблицы и 93 % для приведенной ниже таблицы, потому что только 93 % выборки выбрали одну из четырех показанных марок. Напротив, результаты для SPSS все разные. Фактически, все они примерно на 8% выше в таблице ниже по сравнению с таблицей выше. Причина этого в том, что он использует несколько странную формулу. Проценты SPSS были рассчитаны путем деления количества людей, выбравших любой вариант, на количество людей, выбравших один или несколько вариантов. Глядя на данные AAPT, в приведенной выше таблице SPSS показывает 8,8%, что вычисляется как 44/49.8, где 498 — доля людей, выбравших один или несколько вариантов ответа (т.
е. общая выборка). Однако в приведенной ниже таблице показано 9,5%, что составляет 44/462, где 462 — это количество людей, выбравших один или несколько из четырех брендов, использованных для построения таблицы.Важно понимать, что расхождения между результатами вызваны наличием данных, в которых некоторые люди не выбрали ни одну из категорий. Если данные не страдают от этой проблемы, разные программы дадут одинаковые результаты. Кроме того, разница заключается в одном из тех редких случаев, когда одна из программ выдает числа, которые в большинстве случаев бесполезны (т. е. результаты, полученные при вычислении SPSS во второй таблице, вводят в заблуждение, поскольку большинство связаны с долей респондентов, выбравших вариант, и такая интерпретация неверна. К сожалению, расчет SPSS является «стандартным» и используется большинством программ анализа данных (которые, как правило, были написаны в предположении, что люди вынуждены выберите хотя бы один вариант)
Причина, по которой программы делают это по-разному
Как уже упоминалось, в ситуациях, когда NET составляет 100%, два метода дадут один и тот же ответ.
Табличный метод – это традиционный подход. В традиционном опросе NET всегда будет 100%, потому что в традиционном опросе, проводимом профессиональным исследователем, всегда будет вариант «Ни один из этих», и, таким образом, оба метода дают одинаковые результаты. Таким образом, традиционные программы используют метод на основе таблиц, потому что он быстрее вычисляется, когда нет пропущенных данных. Однако в ситуациях, когда есть вероятность того, что данные будут каким-то образом запутаны, предпочтительнее использовать метод на основе респондентов, поскольку он имеет следующие преимущества:- Возможность проблемы отмечена тем, что NET не равна 100 %.
- Оцениваемые значения являются разумными (т. е. гораздо проще объяснить, что процент представляет собой долю респондентов, чем описывать процент как долю среди респондентов, выбравших хотя бы один вариант ответа).
Таким образом, поскольку многие традиционные программы разрабатываются в предположении, что данные относительно чисты, они используют метод, который лучше всего подходит для таких ситуаций, тогда как более современные программы используют альтернативный метод, поскольку он более безопасен в современном мире.
где данные часто беспорядочны.Как переключаться между различными типами расчета множественных ответов
В большинстве программ можно заставить программу изменить способ вычисления процентов для вопросов с множественными ответами. В программах, использующих метод на основе респондентов, хитрость заключается в том, чтобы отфильтровать таблицу так, чтобы она содержала только респондентов, выбравших один или несколько вариантов. В программах, использующих табличный метод, хитрость заключается в том, чтобы не сообщать программе, что это вопрос с несколькими ответами.
Использование сводного отчета для руководства очисткой данных
Как минимум, сводный отчет следует просмотреть, чтобы убедиться, что результаты имеют смысл, что по существу включает сравнение результатов с тем, что уже известно об изучаемой совокупности (это обсуждается подробно в Проверка репрезентативности), и что они правдоподобны (например, если респондент утверждает, что у него 99 мобильных телефонов, то это говорит о наличии проблемы.
Более тщательная очистка данных включает проверку того, что двусторонние отношения между переменными Например, при проверке данных о прибыльности фирмы полезно рассмотреть прибыльность на количество сотрудников, поскольку для фирмы может иметь смысл внести 10 миллионов долларов прибыли в отрасль, но менее вероятно, что В фирме работает 1 сотрудник. Это делается путем создания перекрестных таблиц. Как правило, это делается в рамках основного анализа данных, а не как отдельный этап подготовки данных.
Самая сложная часть очистки данных — решить, что делать с «грязными» данными. Рассмотрим в качестве примера файл данных, в котором указано, что летом человек ходит на пляж 99 раз в месяц. Возможны следующие варианты:
- Определить, что проблема заключается в неверных метаданных. Например, может случиться так, что значение 99 не представляет количество поездок на пляж, а указывает на то, что человек действительно сказал «не знаю». См. Исправление метаданных.
- Удалить неверное значение, заменив -99 со специальным кодом, указывающим, что данные недействительны. Это приводит к отсутствующим значениям и часто возникает необходимость использовать специальные инструменты анализа, которые могут работать с отсутствующими данными. См. Отсутствующие значения.
- Измените значение (например, замените 99 на 9). См. Перекодирование переменных.
- Измените значение на несколько значений и назначьте вероятности для разных значений. Хотя это может быть наиболее подходящим решением, подобное чрезвычайно редко встречается в реальном коммерческом исследовании, и поэтому этот подход, известный как множественное вменение, больше не обсуждается.
- Удалить всю запись грязных данных, что включает в себя предположение, что эта единственная ошибка указывает на то, что все их данные неверны. См. Удаление респондентов.
Чтобы решить, какой из них подходит, нам нужно понять причину некачественных данных (например, ошибки нажатия клавиш, поврежденные данные, ошибка респондента), как если бы мы очищали данные, не понимая причины проблем, мы подвергаемся высокому риску того, что другие данные, которые мы не определили как грязные, окажутся неточными и что «чистые» данные не будут точно отражать рынок.
Кросс-таблицы
Таблица, показывающая взаимосвязь между двумя вопросами в опросе, называется кросс-таблицей.
Чтение перекрестных таблиц
Следующая таблица представляет собой перекрестную таблицу возраста в зависимости от того, есть ли у кого-либо указанный номер телефона.
В этой таблице показано количество наблюдений с каждой комбинацией двух вопросов в каждой ячейке таблицы. Количество наблюдений часто называют подсчетом. Мы видим, например, что 185 человек в возрасте от 18 до 34 лет не имеют незарегистрированного номера телефона.
Проценты столбцов
Проценты столбцов показаны в таблице выше. Эти проценты вычисляются путем деления счетчиков для отдельной ячейки на общее количество счетчиков для столбца. Процент столбца показывает долю людей в каждой строке от числа людей в столбце. Например, 24 % всех людей, не зарегистрированных в списке, имеют возраст от 18 до 34 лет в выборке (т. е. 185/779 = 24 %), и, таким образом, мы можем сказать, незарегистрированный номер телефона в возрасте от 18 до 24 лет.
Проценты строк
Проценты строк вычисляются путем деления числа для ячейки на общий размер выборки для этой строки. Процент строки показывает долю людей в категории столбца среди людей в строке. Например, поскольку 185 человек в возрасте от 18 до 34 лет в столбце Нет и всего 275 человек в возрасте от 18 до 34 лет, процент строк составляет 67 % (т. е. 185 / 275), и, таким образом, мы можем сказать, По оценкам, 67% людей в возрасте от 18 до 34 лет имеют незарегистрированный номер телефона.
Выяснение того, показывает ли таблица проценты строк или столбцов
В некоторых кросс-таблицах нечетко указывается, являются ли проценты процентами строк или столбцов (например, в примере ниже). При чтении таблицы самый простой способ проверить, показывает ли она проценты по строкам или столбцам, — это проверить, в каком направлении числа в сумме дают 100%. В приведенной выше таблице проценты в сумме составляют 100% в каждом столбце, и, кроме того, это указано в таблице NET, и, таким образом, показывает проценты столбцов.
Проверка того, составляют ли проценты в сумме 100 %, работает только в том случае, если категории в строках (или столбцах) являются взаимоисключающими. Если данные взяты из вопроса с несколькими ответами, это сложнее, так как проценты в сумме превысят 100% (поскольку люди могут принадлежать более чем к одной категории). Пример показан в таблице ниже, в которой показаны проценты столбцов двух разных типов:
- Процент людей, выбравших каждый вариант (% действительных случаев).
- Процент выбранных вариантов (% от общего числа упоминаний).
(более подробно о том, как интерпретировать такие таблицы, см. в разделе «Подсчитанные значения и пропущенные значения в вопросах с несколькими ответами»).
В приведенной ниже кросс-таблице проценты не дают в сумме 100 % ни в одном из направлений, и в маркировке таблицы нет ничего, чтобы было ясно, показаны ли в таблице проценты строк или столбцов.
В большинстве случаев, когда в кросс-таблице отображается процентное значение, это процент столбца.
В этой таблице показаны проценты столбцов. Там, где трюк сложения процентов не работает, как в этом примере, есть несколько способов сделать вывод, является ли конкретный набор чисел процентами строк или столбцов.- Положение размеров выборки на столе. По соглашению, если размеры выборки отображаются в верхней части таблицы, то отображаются проценты столбца, а если размеры выборки появляются в столбце, то отображаются проценты строки. В приведенном выше примере размеры выборки показаны вверху, что позволяет предположить, что два показанных процента являются различными вариантами процентов столбца.
- Положение знаков % в таблице. По соглашению, если символ % появляется только вверху каждого столбца в таблице, то отображаются проценты столбца, а если символ % появляется в начале каждой строки, то отображаются проценты строки.
- Степень разброса сумм процентов. Например, в приведенной ниже таблице мы видим, что проценты довольно сильно различаются в каждом столбце, но в каждой строке они достаточно схожи, что указывает на то, что таблица показывает проценты столбца (аналогично, если бы изменчивость была больше в строках, это будет означать, что были показаны проценты строк).
Прочие статистические данные
Чаще всего перекрестные таблицы показывают проценты. Однако если переменные не являются категориальными, в ячейках кросс-таблицы отображаются другие статистические данные, такие как средние значения, медианы и корреляции.
Тесты на значимость
Тест на значимость — это способ определить, может ли конкретная разница быть значимой или случайной.
Ошибка выборки
Представьте, что вы проводите исследование среди 200 потребителей и обнаруживаете, что 41% назвали Coca-Cola своим любимым безалкогольным напитком. Теперь представьте, что вы провели еще одно исследование и обнаружили, что в следующем исследовании 40% людей предпочитают Coca-Cola. И представьте, что вы провели третье исследование и обнаружили, что 43% людей предпочитают Coca-Cola. Что вы можете сделать из различий между этими исследованиями? Есть три объяснения:
Объяснение 1: Мир каким-то образом менялся между каждым из этих исследований, и доля людей, предпочитающих Coca-Cola, немного снизилась, а затем увеличилась (т.
е. выросла с 41% до 40%, а затем до 43%).Объяснение 2: Разница между двумя исследованиями — это случайный шум. В частности, поскольку в каждом исследовании участвовало всего 200 человек, следует ожидать, что мы получим небольшие различия между их результатами. Или, говоря жаргоном, ошибка выборки. 9
Тесты значимости чтобы отразить значимое различие в мире в целом (т. е. объяснение 1 выше), или это просто случайность, вызванная ошибкой выборки (т. е. объяснение 2).
Существует много тысяч различных тестов значимости с экзотическими названиями, такими как лямбда Уилка, точный критерий Фишера и так далее. Однако при анализе данных опроса, как правило, нет необходимости вдаваться в такие подробные сведения о том, какой тест использовать и когда, поскольку большинство тестов значимости, которые применяются при анализе реальных опросов, представляют собой либо исключительные тесты, либо сравнения столбцов.
Исключения тестов
Рассмотрим следующую диаграмму из Displayr.
Просматривая ряд Coca-Cola, мы видим, что:- 65% людей в возрасте от 18 до 24 лет предпочитают Coca-Cola.
- 41% людей в возрасте от 25 до 29 лет предпочитают Coca-Cola.
- 43% людей в возрасте от 30 до 49 лет предпочитают Coca-Cola.
- 40% людей в возрасте 50 лет и старше предпочитают Coca-Cola.
Ожидается, что мы получим разные результаты в каждой из возрастных групп. Процесс отбора людей для участия в опросе означает, что по чистой случайности мы ожидаем, что получим слегка отличающиеся результаты в разных возрастных группах, даже если на самом деле между возрастными группами нет различий в предпочтениях. Coca-Cola (т. е. из-за ошибки выборки). Однако уровень предпочтения для лиц в возрасте от 18 до 24 лет существенно выше. На диаграмме ниже цвет шрифта и стрелка указывают на то, что этот результат значительно выше. То есть, поскольку результат был отмечен как статистически значимый, подразумевается, что гораздо более высокий результат, наблюдаемый для лиц в возрасте от 18 до 24 лет, является не просто случайностью и означает, что среди населения в целом верно, что от 18 до 24 лет имеют более высокий уровень предпочтения Coca-Cola.
Глядя в другое место в таблице, мы видим, что: предпочтение диетической колы кажется низким среди людей в возрасте от 18 до 24 лет, показатели Pepsi относительно высоки среди людей в возрасте от 30 до 49 лет и так далее. Каждый из этих результатов является примером тестов-исключений, которые представляют собой статистические тесты, определяющие результаты, которые в некотором роде являются исключениями из нормы. [примечание 2]
Теперь внимательно посмотрите на строку Coke Zero. Оценка для 18-24-летних меньше, чем вдвое меньше, чем в других возрастных группах. Однако это не отмечено как значимое, и, таким образом, можно сделать вывод о том, что относительно низкий балл для 18–24-летних может быть случайностью и не отражает истинной разницы в популяции в целом. Слово «может» выделено курсивом, чтобы подчеркнуть ключевой момент: нет никакого способа узнать наверняка, отражает ли низкий балл среди молодых людей в опросе разницу в популяции в целом или это просто странный результат, который происходит в этот конкретный образец.
Таким образом, все тесты значимости являются всего лишь ориентирами. Они редко что-либо доказывают, и нам всегда нужно применять здравый смысл при их интерпретации.Сравнение столбцов
В таблице ниже показаны точно такие же данные из того же опроса, что и выше. Однако в то время как на приведенной выше диаграмме результаты показаны как исключения, здесь вместо этого показан более сложный тип теста значимости, называемый сравнением столбцов. Каждый из столбцов представлен буквой, показанной внизу страницы. Некоторые ячейки таблицы содержат буквы, указывающие на то, что результат в ячейке значительно выше результатов в перечисленных столбцах. Например, глядя на строку Coca-Cola, появление b c d указывает на то, что предпочтение Coca-Cola на уровне 65 % среди 18-24-летних значительно выше, чем оценки предпочтения 25-29-летних.летние (б), от 30 до 49 лет (в) и люди в возрасте 50 лет и старше (г). То, что буква в нижнем регистре, говорит нам о том, что разница не является сверхсильной (в исключении, показанном выше, длина стрелок указывает на степень статистической значимости).
Обратите внимание, что хотя многие выводы, которые мы можем сделать из этой таблицы, аналогичны выводам из приведенной выше таблицы, между ними есть некоторые отличия. Например, на приведенной выше диаграмме мы пришли к выводу, что предпочтение диетической колы среди молодежи в возрасте от 18 до 24 лет было значительно ниже, чем среди населения в целом. Однако сравнение столбцов говорит нам только о том, что лица в возрасте от 18 до 24 лет имеют более низкий балл, чем лица в возрасте от 30 до 49 лет.s (т. е. мы знаем это, потому что значение a для лиц в возрасте от 30 до 49 лет говорит нам о том, что они имеют более сильное предпочтение, чем лица в возрасте от 18 до 24 лет, представленные в столбце a).
Почему два способа выполнения тестов дают разные результаты? Есть технические пояснения. [примечание 3] Но на самом деле они сводятся к следующему: в разных подходах используются немного разные технические методы и, следовательно, получаются немного разные результаты.
Полезная аналогия состоит в том, чтобы подумать о различных способах сообщения новостей: мы можем рассказать об одной и той же истории по телевидению, в газете и в блоге, и каждый из способов в конечном итоге будет подчеркивать несколько разные аспекты правды.Детерминанты статистической значимости
Существует множество различных факторов, влияющих на то, признается ли конкретная разница статистически значимой или нет, включая:
- Размер сравниваемых различий (т. е. чем больше разница, тем больше вероятность это будет существенно). Это точно такая же идея, которая обсуждается на странице «Определение размера выборки».
- Размер выборки. Различия, наблюдаемые при больших размерах выборки, скорее всего, будут статистически значимыми.
- Конкретный уровень достоверности тестирования.
- Количество технических допущений, сделанных в тесте (например, допущений о нормальности). В целом, чем меньше делается допущений, тем ниже вероятность того, что результат будет считаться статистически значимым.
- Если и как данные были взвешены. Чем сильнее эффект взвешивания, тем меньше вероятность того, что результаты будут статистически значимыми.
- Количество просматриваемых таблиц и размер таблиц. Чем больше анализов просматривается, тем выше вероятность случайных результатов.
- Как были собраны данные (в частности, какой подход к выборке был принят).
- Техническая квалификация лица, написавшего программное обеспечение, проводящее тест. В частности, большинство формул, представленных во вводных курсах по статистике, учитывают только первые три из перечисленных выше проблем, а большинство коммерческих программ неправильно обрабатывают взвешивание. Общая неоднозначность статистического тестирования с точки зрения его неспособности давать окончательные выводы в сочетании с большим количеством технических ошибок, допущенных при практическом применении значимых тестов, вновь приводят к тому же выводу, который был изложен ранее: статистические тесты есть не более и не что иное. менее чем полезный способ выявления интересных результатов, которые могут отражать то, как устроен мир, но также могут быть просто случайными случайностями.
Примечания
- Перейти ↑ Или, если быть более точным, ошибка выборки — это разница между тем, что мы наблюдаем в случайной выборке, и тем, что мы получили бы, если бы опросили население.
- Jump up↑ Термин исключительный тест не является стандартным термином. Наиболее близким к стандартному термину для такого теста является студенческие остатки в таблицах непредвиденных обстоятельств, но даже это довольно неясный термин.
- Jump up↑ В частности, тест исключений имеет большую статистическую мощность из-за объединения выборки, сравнения столбцов не являются транзитивными, а размер выборки для сравнения столбцов меньше, чем для тестов исключений.
Корреляция
«Корреляция» относится к степени, в которой две вещи имеют статистическую взаимосвязь. Например, если люди с более высокими доходами потребляют больше вина, мы говорим, что потребление вина коррелирует с доходом.
Фильтрация
Фильтрация данных включает ограничение анализа определенной подгруппой выборки. Например, если вы просматриваете данные о людях из вашей выборки, которые являются мужчинами в возрасте до 50 лет, вы отфильтровали данные.
Создание фильтров
Фильтры создаются с использованием правил, определяющих, какие респонденты должны быть включены в анализ, а какие исключены. Хотя есть некоторые нюансы, обычно фильтры создаются по различным правилам И и ИЛИ. Например, ваше правило может включать людей моложе 50 лет И являются мужчинами, или правило может включать людей моложе 50 лет ИЛИ мужчин. Между различными программами анализа данных нет согласованности с точки зрения того, как создаются фильтры. Например, в SPSS фильтры нужно создавать, вводя выражение. Например, фильтр мужчин моложе 50 лет будет введен как q2 <= 7 и q3 == 1, где q2 и q3 – это имена переменных, а 7 и 1 – конкретные значения, представляющие возрастную и гендерную категории соответственно.
Вместо этого Q использует ту же базовую логику, но представленную в формате типа «дерево» (слева), тогда как Displayr использует менее гибкую, но более простую в использовании сетку флажков.
Переменные фильтра
Почти все программы рассматривают создание фильтра как эквивалент создания новой переменной, где переменная содержит две категории, одна из которых представляет людей в фильтре, а другая представляет людей, не входящих в фильтр. группа фильтров. Как правило, они добавляются в файл данных, что позволяет использовать их повторно.
Применение фильтров
Созданный фильтр обычно можно использовать повторно, выбрав его из списка сохраненных фильтров. Единственным заметным исключением из этого является SPSS, в котором вам нужно создать новый фильтр, но вы можете сделать это, используя старый фильтр (например, если ранее созданный фильтр назывался var001, тогда выражение для нового фильтра при его повторном использовании будет var001.
Еще одно различие между SPSS и большинством программ заключается в том, что в SPSS фильтр либо включен, либо выключен, тогда как в других программах фильтр применяется специально для отдельных анализов.Подсчитанные значения и пропущенные значения в вопросах с несколькими ответами
Подсчитанные значения
В вопросе с одним ответом обычно очевидно, что правильный способ вычисления пропорций состоит в том, чтобы вычислить количество людей, выбравших категорию, и разделить его на общее количество людей, выбравших хотя бы одну категорию. На интуитивном уровне имеет смысл, что проценты данных множественных ответов будут вычисляться таким же образом. Однако способ хранения данных не позволяет сделать это так просто. Обычно данные о множественных ответах хранятся так, чтобы для каждого бренда существовала одна переменная. Однако не всегда понятно, как анализировать именно эту переменную.
В некоторых файлах данных фрейм кода будет настроен как:
0 Не выбрано 1 выбрано
В такой ситуации обычно совершенно очевидно, что правильный способ вычисления пропорций состоит в том, чтобы определить долю людей с 1 в их данных (это становится более сложным, если отсутствуют данные; это обсуждается в следующем раздел).
Или, выражаясь по-другому, правильный способ вычисления пропорций состоит в подсчете большего значения (т. е. 1).Аналогичным образом, если метаданных нет и переменная содержит только 0 и 1, по-прежнему очевидно, что следует учитывать единицы.
Однако сложность усложняется, когда в данных есть значения, отличные от 0 и 1. Например, иногда кодовый кадр будет таким:
1 Да 2 Нет
Для человека очевидно, что при ответе «да» нужно считать ответы. Однако в некотором смысле это противоположно предыдущим примерам, так как теперь мы подсчитываем наименьшее из наблюдаемых значений, а не наибольшее.
Из-за потенциальной двусмысленности большинство программ работают так, что они либо заставляют пользователя указать конкретное значение (например, SPSS требует, чтобы пользователь указал Подсчитанное значение ), либо дают пользователю возможность для проверки и изменения настройки. Например, в Q пользователь указывает, должен или не должен выполняться анализ Подсчитать это значение , а в Displayr у пользователя есть возможность Выбрать категории .
Множественные данные ответа, где переменные содержат несколько значений
Иногда переменные содержат более двух значений, поэтому совсем не очевидно, какое из значений следует считать. Есть два очень разных примера этого.
Случай A: данные Max-Multi
Если данные представлены в формате max-multi, во время создания набора множественных ответов необходимо выбрать другие параметры.
В SPSS, например, данные должны быть выбраны как Категории при определении множественных наборов ответов, тогда как в Q есть специальный тип вопроса Pick Any – Compact разработан для этого типа данных.
Случай B: Перекодирование вопросов-таблиц
Часто бывает полезно рассматривать некоторые типы вопросов-таблиц, как если бы они представляли собой вопросы с несколькими ответами. Чаще всего при вопросе, который заставляет людей оценивать согласие по пятибалльной шкале (например, Абсолютно не согласен, Отчасти не согласен, Ни согласен, ни не согласен, Отчасти согласен, Полностью согласен , этот вопрос обычно преобразуется в 2 высших балла (т.
е. NET из В некоторой степени согласен и Совершенно согласен. Существует множество способов сделать это. Однако самый простой – рассматривать данные как множественный ответ и подсчитывать несколько значений. Например, подсчитать значения 4 и 5 (при условии, что они соответствуют В некоторой степени согласен и Полностью согласен). В большинстве программ это можно сделать, перекодировав существующие переменные так, чтобы они имели только два значения (например, 0 и 1), а затем обработав данные, как если бы они были получены из вопроса с несколькими ответами. В случае Q и Отображение и то, и другое позволяют указывать несколько подсчитываемых значений (т. е. нет необходимости перекодировать переменные в этих программах).0014Отсутствующие значения
В следующей таблице показаны данные для первых 10 из 498 респондентов из примера мобильных устройств. Обратите внимание, что, например, первый респондент предоставил данные только по брендам 1, 2 и 7 (т. е. не указал значения для всех остальных).
Эти данные взяты из вопроса, в котором людям показывали список брендов и спрашивали, какие из них они показывали раньше (т. е. это вопрос Aided Awareness). Если у респондентов отсутствуют значения (обозначены как .), это связано с тем, что они указали в предыдущем вопросе о неконтролируемой осведомленности, что им известно о брендах.Единственный способ вычислить правильную сводную таблицу для этого вопроса с несколькими ответами – это если данные были настроены таким образом, чтобы программа анализа знала, что правильная интерпретация заключается в том, что человек знает о данном бренде, если он сказал да, или у них отсутствуют данные. По умолчанию ни одна программа анализа этого не сделает. Например, итоговые сводные таблицы в SPSS и Q показаны ниже. Оба неверны в данном случае.
Сводная таблица множественных ответов SPSS с отсутствующими данными Сводная таблица множественных ответов Q с отсутствующими значениями основание n = от 0 до 489 Чтобы лучше понять данные и как рассчитать действительные проценты, полезно взглянуть на следующую таблицу, в которой указано количество респондентов, у которых есть данные «Да», «Нет» или «Отсутствуют данные» для каждого варианта.
Глядя на приведенную выше таблицу SPSS, 21,5%, показанные для ответов AAPT, были рассчитаны путем деления 78 человек, которые сказали «Да» для AAPT, на общее количество записей «Да» для всех брендов. Менее очевидно, что 71,6 %, показанные для Процента случаев , были рассчитаны путем деления 78 на 106, где 106 – это число людей, давших ответ “да” в данных по крайней мере для одного из брендов (это число не показано на таблицы и не может быть выведено из таблицы). При наличии недостающих данных ни одна из этих статистических данных не имеет полезного значения (т. е. они не являются оценками, относящимися к совокупности пользователей телефонов).Таблица, рассчитанная Q (вверху и справа), показывает 17,6% для AAPT. Это было рассчитано путем деления 78 на общее количество людей, сказавших «Да» или «Нет» в отношении AAPT (т. е. 17,6% = 78/(376 + 78)). Этот процент действительно имеет реальное значение, которое полезно в некоторых контекстах. Интерпретация заключается в том, что 17,6% людей, спрашивавших, знали ли они о AAPT, ответили, что знали.
Однако в этом конкретном примере, где мы знаем, что все, у кого отсутствовали данные, знали об AAPT, вычисление Q по умолчанию также бесполезно.Отсутствуют данные Нет Да Всего ААПТ 44 376 78 498 Новый тел. 9 452 37 498 Единый телефон 124 295 79 498 Оптус 444 44 10 498 Оранжевый 214 234 50 498 Телстра 436 44 18 498 Virgin Mobile 109 330 59 498 Водафон 373 97 28 498 Водафон 373 97 28 498 Всего 1753 1872 359 3984 При таком типе данных правильный расчет состоит в том, чтобы вычислить вспомогательную осведомленность как долю людей, сказавших «да» или имеющих отсутствующие данные, и разделить ее на общее количество людей в исследовании.
Например, в случае AAPT правильная пропорция составляет 24,5% (т. е. (44 + 78) / 49).8). В следующей таблице показаны правильные пропорции для всех марок:Марка Осведомленность с помощью ААПТ 24% Новый тел. 9% Единый телефон 41% Оптус 91% Оранжевый 53% Телстра 91% Virgin Mobile 34% Водафон 81% Использование программного обеспечения для правильного вычисления пропорций
Стандартный способ исправить данные:
- Перекодировать переменные таким образом, чтобы отсутствующие значения были перекодированы как имеющие значение 1.
- Если его еще нет в данных, создайте альтернативу «Ни один из этих» (это необходимо, потому что SPSS и некоторые из более старых пакетов анализа требуют, чтобы каждый респондент дал хотя бы один ответ «Да», чтобы проценты были правильно рассчитаны ).
Стандартный метод можно использовать и в Q, и в Displayr, но в обеих этих программах есть более простой способ решить эту проблему.
Вычисление правильных пропорций в Displayr
- Выберите набор переменных, соответствующий вопросу с несколькими ответами, в разделе Наборы данных .
- Справа выберите Свойства > ЗНАЧЕНИЯ ДАННЫХ > Отсутствующие данные , выберите Включить в анализы для каждой из категорий и нажмите ОК .
- Справа выберите Свойства > ЗНАЧЕНИЯ ДАННЫХ > Выбрать категории и убедитесь, что выбраны Да и Отсутствующие данные, и нажмите OK .
Вычисление правильных пропорций в Q
- На вкладке Таблицы щелкните правой кнопкой мыши одну из категорий вопроса и выберите Значения .
- Заполните диалоговое окно, как показано ниже.
Примеры
Мобильные телефоны
Это исследование относится к австралийскому рынку мобильных (сотовых) телефонов.
Анкета: Mobiles Questionnaire.pdf
Файл данных SPSS: Mobiles.sav
Colas
Это исследование относится к рынку колы.
Анкета: Colas Questionnaire.pdf
Файл данных SPSS: Colas.sav
Что такое размер эффекта и почему он имеет значение? (Примеры)
Опубликован в 22 декабря 2020 г. к Прита Бхандари. Отредактировано 17 ноября 2022 г.
Размер эффекта показывает, насколько значимой является взаимосвязь между переменными или разница между группами. Он указывает на практическую значимость результатов исследования.
Большой размер эффекта означает, что результат исследования имеет практическое значение, в то время как небольшой размер эффекта указывает на ограниченное практическое применение.
ПримечаниеЕсть несколько способов сообщить о результатах. В этой статье мы следуем рекомендациям APA.Содержание
- Почему размер эффекта имеет значение?
- Как рассчитать размер эффекта?
- Как узнать, мал размер эффекта или велик?
- Когда следует рассчитывать величину эффекта?
- Часто задаваемые вопросы о размере эффекта
Почему размер эффекта имеет значение?
В то время как статистическая значимость показывает, что эффект существует в исследовании, практическая значимость показывает, что эффект достаточно велик, чтобы иметь значение в реальном мире. Статистическая значимость обозначена цифрой 9.2857 p значений, тогда как практическая значимость представлена величинами эффекта.
Статистическая значимость сама по себе может ввести в заблуждение, поскольку на нее влияет размер выборки. Увеличение размера выборки всегда повышает вероятность обнаружения статистически значимого эффекта, независимо от того, насколько мал этот эффект на самом деле в реальном мире.
Напротив, величина эффекта не зависит от размера выборки. Только данные используются для расчета величины эффекта.
Вот почему необходимо сообщать о величине эффекта в исследовательских работах, чтобы указать на практическую значимость открытия. Руководящие принципы APA требуют сообщать о размерах эффекта и доверительных интервалах, где это возможно.
Пример: статистическая значимость против практической значимости В крупном исследовании сравнивались два метода снижения веса с участием 13 000 участников контрольной группы вмешательства и 13 000 участников экспериментальной группы вмешательства. Контрольная группа использовала научно обоснованные методы похудения, в то время как экспериментальная группа использовала новый метод, основанный на приложении.Через шесть месяцев средняя потеря веса (кг) в экспериментальной группе вмешательства ( M = 10,6, SD = 6,7) была незначительно выше, чем средняя потеря веса в контрольной группе вмешательства ( M = 10,5, SD = 6,8).
Эти результаты были статистически значимыми ( p = 0,01). Однако разница всего в 0,1 кг между группами незначительна и на самом деле не говорит вам о том, что один метод следует предпочесть другому.
Добавление показателя практической значимости показало бы, насколько многообещающим является это новое вмешательство по сравнению с существующими вмешательствами.
Как рассчитать размер эффекта?
Существуют десятки показателей величины эффекта. Наиболее распространенными величинами эффекта являются Коэна 9.2857 d и Pearson’s r . d Коэна измеряет размер разницы между двумя группами, в то время как r Пирсона измеряет силу связи между двумя переменными.
Магазин Коэна
dCohen’s d предназначен для сравнения двух групп. Он берет разницу между двумя средними значениями и выражает ее в единицах стандартного отклонения. Он говорит вам, сколько стандартных отклонений лежит между двумя средними значениями.
Формула Коэна d Объяснение - = среднее значение группы 1
- = среднее значение группы 2
- с = стандартное отклонение
Выбор стандартного отклонения в уравнении зависит от плана вашего исследования. Вы можете использовать:
- объединенное стандартное отклонение, основанное на данных обеих групп,
- стандартное отклонение от контрольной группы, если ваш план включает контрольную и экспериментальную группы,
- стандартное отклонение от данных предварительного тестирования, если ваш план повторных измерений включает предварительное и последующее тестирование.
При коэффициенте Коэна d , равном 0,015, практическая значимость вывода о том, что экспериментальное вмешательство было более успешным, чем контрольное, практически не имеет значения.
Пирсонс
рПирсона r , или коэффициент корреляции измеряет степень линейной зависимости между двумя переменными.
Формула довольно сложная, поэтому лучше всего использовать статистическое программное обеспечение для расчета 9 Пирсона.2857 r точно из необработанных данных.
Pearson’s r формула Объяснение - r xy = сила корреляции между переменными x и y
- n = объем выборки
- ∑ = сумма следующих
- X = каждое значение x-переменной
- Y = каждое значение переменной y
- XY = произведение каждой оценки переменной x на соответствующую оценку переменной y
Основная идея формулы состоит в том, чтобы вычислить, какая часть изменчивости одной переменной определяется изменчивостью другой переменной.
r компании Pearson — это стандартизированная шкала для измерения корреляций между переменными, что делает ее безразмерной. Вы можете напрямую сравнивать силы всех корреляций друг с другом.
Одно предостережение заключается в том, что r Пирсона, как и d Коэна, можно использовать только для интервальных или относительных переменных. Другие меры размера эффекта должны использоваться для порядковых или номинальных переменных.
Получение отзывов о языке, структуре и форматировании
Профессиональные редакторы вычитывают и редактируют вашу статью, уделяя особое внимание:
- Академический стиль
- Расплывчатые предложения
- Грамматика
- Согласованность стиля
См. пример
Как узнать, мал размер эффекта или велик?
Размеры эффектов можно разделить на малые, средние и большие в соответствии с критериями Коэна.
Критерии Коэна для малых, средних и больших эффектов различаются в зависимости от используемого измерения величины эффекта.
Размер эффекта Коэна д Пирсонс р Маленький 0,2 от .1 до .3 или от -.1 до -.3 Средний 0,5 от .3 до .5 или от -.3 до -.5 Большой 0,8 или выше .5 или больше или -.5 или меньше Число d Коэна может принимать любое число от 0 до бесконечности, а число r Пирсона находится в диапазоне от -1 до 1.
В целом, чем больше d Коэна, тем больше размер эффекта. Для Пирсона r , чем ближе значение к 0, тем меньше размер эффекта. Значение, близкое к -1 или 1, указывает на более высокий размер эффекта.
Pearson r также говорит вам кое-что о направлении отношений:
- Положительное значение (например, 0,7) означает, что обе переменные одновременно увеличиваются или уменьшаются.
- Отрицательное значение (например, -0,7) означает, что одна переменная увеличивается при уменьшении другой (или наоборот).
Критерии малого или большого размера эффекта также могут зависеть от того, какие исследования обычно проводятся в вашей конкретной области, поэтому обязательно проверяйте другие документы при интерпретации размера эффекта.
Когда следует рассчитывать размер эффекта?
Полезно рассчитать величину эффекта еще до начала исследования, а также после завершения сбора данных.
Перед началом учебы
Зная ожидаемый размер эффекта, вы можете вычислить минимальный размер выборки, необходимый для статистической мощности, достаточной для обнаружения эффекта такого размера.
В статистике мощность относится к вероятности того, что проверка гипотезы обнаружит истинный эффект, если таковой имеется. Статистически мощный тест с большей вероятностью отклонит ложноотрицательный результат (ошибка типа II).
Если вы не обеспечите достаточную мощность в своем исследовании, вы не сможете обнаружить статистически значимый результат, даже если он имеет практическое значение.
В этом случае вы не отвергаете нулевую гипотезу, даже если имеет место реальный эффект.Выполняя анализ мощности, вы можете использовать установленный размер эффекта и уровень значимости, чтобы определить размер выборки, необходимый для определенного уровня мощности.
После завершения учебы
После того, как вы соберете данные, вы сможете рассчитать фактические величины эффекта и указать их в разделах резюме и результатов своей статьи.
Величина эффекта — это необработанные данные в исследованиях метаанализа, поскольку они стандартизированы и их легко сравнивать. Метаанализ может объединить размеры эффекта многих связанных исследований, чтобы получить представление о среднем размере эффекта конкретного вывода.
Но исследования метаанализа также могут пойти еще дальше и также показать, почему размеры эффекта могут различаться в исследованиях по одной теме. Это может породить новые направления исследований.
Часто задаваемые вопросы о размере эффекта
org/FAQPage”>
- Что такое размер эффекта?
Размер эффекта показывает, насколько значимой является взаимосвязь между переменными или разница между группами.
Большой размер эффекта означает, что результат исследования имеет практическое значение, в то время как небольшой размер эффекта указывает на ограниченное практическое применение.
- Как рассчитать размер эффекта?
Существуют десятки мер величины эффекта. Наиболее распространенными величинами эффекта являются d Коэна и r Пирсона. d Коэна измеряет размер разницы между двумя группами, в то время как r Пирсона измеряет силу связи между двумя переменными.
- Что такое статистическая мощность?
В статистике мощность относится к вероятности того, что проверка гипотезы обнаружит истинный эффект, если таковой имеется. Статистически мощный тест с большей вероятностью отклонит ложноотрицательный результат (ошибка типа II).
Если вы не обеспечите достаточную мощность в своем исследовании, вы не сможете обнаружить статистически значимый результат, даже если он имеет практическое значение. Ваше исследование может не дать ответа на ваш исследовательский вопрос.
Процитировать эту статью Scribbr
Если вы хотите процитировать этот источник, вы можете скопировать и вставить цитату или нажать кнопку «Цитировать эту статью Scribbr», чтобы автоматически добавить цитату в наш бесплатный генератор цитирования.
Бхандари, П. (2022, 17 ноября). Что такое размер эффекта и почему он важен? (Примеры). Скриббр. Проверено 28 февраля 2023 г., с https://www.scribbr.com/statistics/effect-size/
Процитировать эту статью
Полезна ли эта статья?
Вы уже проголосовали. Спасибо 🙂 Ваш голос сохранен 🙂 Обработка вашего голоса…
Прита имеет академическое образование в области английского языка, психологии и когнитивной нейробиологии. Как междисциплинарный исследователь, она любит писать статьи, объясняющие сложные исследовательские концепции для студентов и ученых.
Анализ перекрестных таблиц: Полное руководство
Попробуйте Qualtrics бесплатно
Бесплатная учетная запись13 минут чтения
Кросс-табулирование — один из наиболее полезных аналитических инструментов и опора индустрии маркетинговых исследований. Кросс-табличный анализ, также известный как анализ таблицы непредвиденных обстоятельств, чаще всего используется для анализа категориальных (номинальная шкала измерений) данных.Если вы хотите провести анализ опроса и сравнить результаты одной или нескольких переменных с результатами другой, есть только одно решение: перекрестная таблица.
Кросс-табуляция (также кросс-табуляция или кросс-таблица) является одним из наиболее полезных аналитических инструментов и основой индустрии маркетинговых исследований. Кросс-табличный анализ, также известный как анализ таблицы непредвиденных обстоятельств, чаще всего используется для анализа категориальных (номинальная шкала измерений) данных.
По своей сути перекрестные таблицы представляют собой просто таблицы данных, в которых представлены результаты всей группы респондентов, а также результаты подгрупп респондентов опроса. С их помощью вы можете исследовать отношения в данных, которые могут быть не очевидны, если смотреть только на общее количество ответов на опрос.
Бесплатная электронная книга: отчет о тенденциях исследования мирового рынка в 2022 году
Что такое кросс-табулирование? (Точное определение)Для точной справки, перекрестная таблица представляет собой двухмерную (или более) таблицу, в которой регистрируется количество (частота) респондентов, обладающих конкретными характеристиками, описанными в ячейках таблицы. Таблицы перекрестных таблиц предоставляют обширную информацию о взаимосвязи между переменными.
Анализ перекрестных таблиц имеет свой уникальный язык с использованием таких терминов, как «баннеры», «заглушки», «статистика хи-квадрат» и «ожидаемые значения». Типичная перекрестная таблица, в которой сравниваются две гипотетические переменные «Город проживания» и «Любимая бейсбольная команда», показана ниже. Независимость города проживания и болельщика этой команды? В ячейках таблицы сообщается частота и процентное соотношение количества респондентов в каждой ячейке.
В этой таблице текстовая легенда кросс-таблицы описывает переменные строки и столбца.
Вы можете создавать и анализировать несколько таблиц в параллельном или последовательном формате. Специалисты по составлению таблиц называют переменные столбцов в этих нескольких таблицах «баннерами», а переменные строк — «заглушками».Но помимо сложного определения, когда следует использовать перекрестную таблицу?
Когда следует использовать перекрестную таблицу?Вы обычно используете перекрестную таблицу, когда у вас есть категориальные переменные или данные, например. информацию, которую можно разделить на взаимоисключающие группы.
Например, категориальной переменной могут быть отзывы клиентов по регионам. Вы делите эту информацию на обзоры по географическим регионам: север, юг, восток, запад или штат, а затем анализируете отношения между этими данными.
Еще один пример использования перекрестных таблиц — опросы о продуктах. Вы можете спросить группу из 50 человек: «Вам нравятся наши продукты?» и используйте перекрестную таблицу, чтобы получить более проницательный ответ.
Вместо того, чтобы просто записывать 50 ответов, вы можете добавить еще одну независимую переменную, например пол, и использовать перекрестную таблицу, чтобы понять, как респонденты мужского и женского пола относятся к вашему продукту.С помощью этой информации вы можете увидеть, что ваши клиенты-женщины предпочитают ваши продукты больше, чем ваши клиенты-мужчины. Затем вы можете использовать эти идеи, чтобы улучшить свои продукты для ваших клиентов-мужчин.
Таким образом, используя две переменные — пол и привлекательность продукта — вместе с перекрестными таблицами, вы можете получить более полную разбивку наборов данных для выявления закономерностей, тенденций или другой полезной информации.
Таким образом, кросс-табулирование отлично подходит для оценки категориальных переменных в исследованиях рынка или ответах на опросы, поскольку вы можете легко сравнивать наборы данных, чтобы обнаружить взаимосвязь между двумя (или более), казалось бы, не связанными элементами.
Другое использование кросс-таблиц
- Вовлеченность и удовлетворенность сотрудников: вы можете оценить, как сотрудники, как мужчины, так и женщины, относятся к своим рабочим ролям в настоящее время. Вы даже можете провести это исследование между отделами и сравнить две или более переменных, чтобы получить лучшее понимание.
- Выходные интервью: почему сотрудники увольняются и что вы могли бы сделать по-другому? Например, существует ли корреляция между уходом сотрудников и продвижением по службе?
- Проблемы отдела: — это проблемы, вызванные одной или несколькими переменными, и если да, то являются ли эти проблемы более распространенными на определенных должностях?
- Оценочные опросы в школах: как учащиеся относятся к материалам курса и достаточно ли времени, потраченного на изучение материала?
- Исследование продукта и обратная связь: как некоторые демографические группы относятся к вашему продукту? Что они хотели бы видеть и как отзывы отличаются от региона к региону? А как насчет удовлетворенности клиентов?
Но если вы готовы выйти за рамки опросов и начать прислушиваться к тому, что говорят ваши потенциальные клиенты и потенциальные клиенты, обязательно ознакомьтесь с нашим руководством по использованию нескольких каналов прослушивания.
Каковы преимущества перекрестных таблиц?В качестве метода статистического анализа, позволяющего проводить категориальную оценку набора данных, кросс-табулирование может помочь выявить переменные или несколько переменных, влияющих на конкретный результат или способных улучшить конкретный результат.
С приведенными выше примерами у вас должно быть хорошее представление о том, как кросс-табулирование можно использовать в определенных контекстах для получения информации. Но у перекрестных таблиц есть несколько других преимуществ:
- Сокращение ошибок: анализ наборов данных может привести к путанице, не говоря уже о точном извлечении из них информации. Используя перекрестные таблицы, вы можете сделать свои наборы данных более управляемыми в масштабе (поскольку они упрощают их и делят на репрезентативные подгруппы).
- Дополнительные сведения: кросс-табуляции анализируют отношения между одной или несколькими категориальными переменными для получения более детальных сведений. Эти идеи могут остаться незамеченными при использовании стандартных подходов (или для их раскрытия потребуется дополнительная работа).
- Полезная информация: , поскольку кросс-таблица упрощает наборы данных и позволяет быстро сравнивать отношения между ними, вы можете быстрее находить ценные сведения и применять новые стратегии по мере необходимости.
Это основные преимущества перекрестных таблиц, но в качестве метода статистического анализа его можно применять к широкому кругу областей исследований и дисциплин, чтобы помочь вам получить больше от ваших данных.
Как выполнять анализ перекрестных таблиц в Microsoft ExcelВ Microsoft Excel таблицы перекрестных таблиц (или кросс-таблицы) можно автоматизировать с помощью сводной таблицы. Вы можете использовать значок сводной таблицы на панели инструментов или щелкнуть Данные > Отчет сводной таблицы и сводной диаграммы .
Кроме того, вы можете нажать Вставить , а затем нажать кнопку Сводная диаграмма .
После нажатия откроется диалоговое окно сводной диаграммы. Выберите данные, которые должны использоваться в перекрестном анализе, и укажите, где вы хотите их разместить.Вы можете поэкспериментировать с отдельными параметрами кросс-таблицы, но выберите столбцы, которые хотите сравнить и проанализировать, чтобы получить необходимую информацию.
Кросс-таблица с анализом хи-квадрат
Статистика хи-квадрат является основной статистикой, используемой для проверки статистической значимости таблицы кросс-табуляции. Тесты хи-квадрат определяют, являются ли две переменные независимыми. Если переменные независимы (не имеют связи), то результаты статистического теста будут «незначимыми», и мы не сможем отвергнуть нулевую гипотезу, что означает, что мы считаем, что между переменными нет связи. Если переменные связаны между собой, то результаты статистического теста будут «статистически значимыми», и мы можем отвергнуть нулевую гипотезу, а это означает, что мы можем констатировать наличие некоторой связи между переменными.
Статистика хи-квадрат вместе с соответствующей вероятностью случайного наблюдения может быть вычислена для любой таблицы. Если переменные связаны (т. е. наблюдаемые связи в таблице будут иметь место с очень низкой вероятностью, скажем, всего 5%), то мы говорим, что результаты являются «статистически значимыми» на уровне 0,05 или 5%.
Это означает, что у переменных мало шансов быть независимыми. Изучающие статистику помнят, что значения вероятности (0,05 или 0,01) отражают готовность исследователя принять ошибку первого рода или вероятность отвергнуть истинную нулевую гипотезу (это означает, что мы думали, что существует связь между переменными, когда не было).
Кроме того, эти вероятности являются кумулятивными, а это означает, что если протестировано 20 таблиц, исследователь может быть почти уверен, что связь между одной из таблиц будет обнаружена ошибочно (20 x 0,05 = 100% вероятность). В зависимости от цены ошибки исследователь может применять более строгие критерии для объявления значимости, такие как 0,01 или 0,005.
Вычисление статистики хи-квадрат для таблиц кросс-таблиц
Статистика хи-квадрат вычисляется путем сначала вычисления значения хи-квадрат для каждой отдельной ячейки таблицы, а затем их суммирования для формирования общего хи-квадрата. значение для таблицы. Значение хи-квадрат для ячейки вычисляется как: (Наблюдаемое значение – Ожидаемое значение)2 / (Ожидаемое значение). Вычисления хи-квадрата выделены серым цветом.
В этой примерной таблице мы видим, что значение хи-квадрат для таблицы равно 19,35 и имеет соответствующую вероятность случайного появления менее одного раза из 1000. Поэтому мы отвергаем нулевую гипотезу об отсутствии различий и делаем вывод что должна быть связь между переменными. Мы можем наблюдать взаимосвязь в двух местах таблицы.
Наиболее очевидным является значение хи-квадрат, вычисленное для каждой ячейки. Мы видим, что ячейки «Ред Сокс и Бостон», «Блю Джейс и Монреаль» и «Ред Сокс и Монпелье, Вермонт» были тремя ячейками, в которых количество наблюдаемых респондентов было больше, чем ожидалось.
Мы также отмечаем, что когда мы изучаем ожидаемые и наблюдаемые частоты, частоты «Янки и Монреаль», «Красные носки и Монпелье, Вермонт» и «Красные носки и Монреаль» оказались меньше, чем ожидалось.Поскольку хи-квадрат ячейки и ожидаемые значения часто не отображаются, эти же отношения можно наблюдать, сравнивая общий процент столбца с процентом ячейки (от общего количества строк). В ячейке «Красные носки и Бостон» мы сравним 41,10% с 64,71% и увидим, что болельщикам «Красных носков» Бостон понравился больше, чем ожидалось. Необходимо соблюдать осторожность при интерпретации взаимосвязей, обнаруженных в любом статистическом анализе. Мы часто хотим «объяснить» или сделать вывод о «причинно-следственной связи» на основе анализа, когда данные либо не предназначены для таких выводов, либо не имеют силы для их подтверждения.
В текущей таблице мы видим, что «Красные носки и Бостон» имели наибольшую разницу между количеством наблюдаемых и ожидаемых респондентов для любой команды и города проживания.
Однако мы должны быть осторожны, делая вывод о том, что «Красные носки» заставили респондентов переехать в Бостон или что Бостон как город проживания вызывает лояльность болельщиков. «Красные носки» и «Бостон» являются наиболее часто наблюдаемыми отношениями между фанатами и городом, но, скорее всего, они совершенно независимы при рассмотрении других концепций или отношений.Кросс-таблицы и хи-квадрат — это эффективные способы анализа данных опроса.
Узнайте, как Qualtrics может упростить анализ кросс-таблиц
Кросс-табулирование: решено
К настоящему моменту вы должны лучше понимать, что такое кросс-табуляция и как ее можно использовать для поддержки ваших исследований и результатов опросов по всем области вашего бизнеса.
Конечно, они являются лишь частью гораздо большего целого — целого, который действительно может помочь вам раскрыть передовые идеи из ваших данных и добиться реальных изменений.
Поскольку мир вокруг нас меняется с молниеносной скоростью, перед вами и вашей исследовательской группой стоит непростая задача понять, что происходит и как вы можете продвигать свою организацию вперед, используя собранные данные.
В нашей бесплатной электронной книге «Современный исследователь в действии» мы рассмотрим, как великие организации, такие как Chobani, Высшая лига бейсбола и L.L. Bean, взломали код того, как использовать исследования и идеи для получения конкурентного преимущества.
Загрузите сейчас, чтобы узнать:
- Как исследования продуктов способствуют успеху
- Как автоматизация помогает быстрее находить ценную информацию
- Как современные исследовательские методы, методы и инструменты могут преобразовать бизнес
Например, категориальной переменной могут быть отзывы клиентов по регионам. Вы делите эту информацию на обзоры по географическим регионам: север, юг, восток, запад или штат, а затем анализируете отношения между этими данными». } }] }
Бесплатная электронная книга: Отчет о тенденциях глобального рынка в 2022 году
Загрузить сейчас
Связанные ресурсы
УЗНАТЬ БОЛЬШЕ
Запросить демонстрацию
Имя *
Пожалуйста, введите ваше имя.
Фамилия *
Пожалуйста, введите вашу фамилию.
Компания *
Пожалуйста, введите название вашей компании.
Должность *
Пожалуйста, введите вашу должность.
Рабочий адрес электронной почты *
Пожалуйста, введите действующий рабочий адрес электронной почты. Ой! Это похоже на личный адрес электронной почты. Введите свой рабочий адрес электронной почты. Ой! Это похоже на личный адрес электронной почты. Введите свой рабочий адрес электронной почты.
Номер телефона *
Пожалуйста, введите действительный номер телефона.
— select an option — AfghanistanAlbaniaAlgeriaAmerican SamoaAndorraAngolaAnguillaAntarcticaAntigua and BarbudaArgentinaArmeniaArubaAustraliaAustriaAzerbaijanBahamasBahrainBangladeshBarbadosBelarusBelgiumBelizeBeninBermudaBhutanBoliviaBonaire, Sint Eustatius and SabaBosnia and HerzegovinaBotswanaBouvet IslandBrazilBritish Indian Ocean TerritoryBrunei DarussalamBulgariaBurkina FasoBurundiCambodiaCameroonCanadaCape VerdeCayman IslandsCentral African RepublicChadChileChinaChristmas IslandCocos (Keeling) IslandsColombiaComorosCongo, Republic of theCook IslandsCosta RicaCroatiaCuraçaoCyprusCzech RepublicCôte d’IvoireDenmarkDjiboutiDominicaDominican RepublicEcuadorEgyptEl SalvadorEquatorial GuineaEritreaEstoniaEswatiniEthiopiaFalkland Islands ( Мальвинские острова)Фарерские островаФиджиФинляндияФранцияФранцузская ГвианаФранцузская ПолинезияФранцузские Южные ТерриторииГабонГамбияГрузияГерманияГанаГибралтарГрецияГренландияГренадаГваделупаГуамГватемалаГернсиГвинеяГвинея-БисауГайанаГаитиОстров Херд и МакД onald IslandsHoly See (Vatican City State)HondurasHong Kong, ChinaHungaryIcelandIndiaIndonesiaIraqIrelandIsle of ManIsraelItalyJamaicaJapanJerseyJordanKazakhstanKenyaKiribatiKuwaitKyrgyzstanLao People’s Democratic RepublicLatviaLebanonLesothoLiberiaLibyaLiechtensteinLithuaniaLuxembourgMacao, ChinaMacedonia, NorthMadagascarMalawiMalaysiaMaldivesMaliMaltaMarshall IslandsMartiniqueMauritaniaMauritiusMayotteMexicoMicronesiaMoldovaMonacoMongoliaMontenegroMontserratMoroccoMozambiqueMyanmarNamibiaNauruNepalNetherlandsNew CaledoniaNew ZealandNicaraguaNigerNigeriaNiueNorfolk IslandNorthern Mariana IslandsNorwayOmanPakistanPalauPalestinePanamaPapua New GuineaParaguayPeruPhilippinesPitcairnPolandPortugalPuerto RicoQatarRomaniaRussia, excluding CrimeaRwandaRéunionSaint BarthélemySaint Helena, Ascension and Tristan da CunhaSaint Kitts and NevisSaint LuciaSaint Martin (French part) Сен-Пьер и МикелонСент-Винсент и ГренадиныСамоаСан-МариноСан-Томе и ПринсипиСаудовская АравияСенегалСербияSe ychellesSierra LeoneSingaporeSint Maarten (Dutch part)SlovakiaSloveniaSolomon IslandsSomaliaSouth AfricaSouth Georgia and the South Sandwich IslandsSouth KoreaSouth SudanSpainSri LankaSudanSurinameSvalbard and Jan MayenSwedenSwitzerlandTaiwan, ChinaTajikistanTanzaniaThailandTimor-LesteTogoTokelauTongaTrinidad and TobagoTunisiaTurkeyTurkmenistanTurks and Caicos IslandsTuvaluUgandaUkraine, excluding CrimeaUnited Arab EmiratesUnited KingdomUnited StatesUnited States Minor Outlying IslandsUruguayUzbekistanVanuatuVenezuelaViet NamVirgin Islands, BritishVirgin Islands, U.
S.Wallis и ФутунаЗападная СахараЙеменЗамбияЗимбабвеАландские острова;
Страна *Пожалуйста, выберите вашу страну.
Пожалуйста, введите свой запрос здесь…
Предоставляя эту информацию, вы соглашаетесь с тем, что мы можем обрабатывать ваши персональные данные в соответствии с нашим Заявлением о конфиденциальности
Отправляя эту форму, вы соглашаетесь получать маркетинговую информацию от Qualtrics как указано в наших Условиях обслуживания и Заявлении о конфиденциальности. Вы можете отменить подписку в любое время.
Да, я хочу получать маркетинговые сообщения о продуктах, услугах и мероприятиях Qualtrics
Укажите, что вы готовы получать маркетинговые сообщения.
Отправляя заявку, я соглашаюсь с Условиями обслуживания и Заявлением о конфиденциальности Qualtrics
Шаг /2
Готовы узнать больше о Qualtrics?
Запросить демонстрацию
Изменение размера таблицы пропорционально обычному размеру (не ширине текста) – TeX
спросил
Изменено 6 лет, 4 месяца назад
Просмотрено 12 тысяч раз
У меня в газете есть пара таблиц.
Я хотел бы, чтобы они оба были немного уменьшены, прибл. 85% от обычного размера.Есть много сообщений о том, как это сделать с помощью
96)$ & $v_0/\mu~(МэВ\cdot fm)$ & $1/\mu~(fm)$\\ \hline $$ -497,726 и $17270$ и $-166,924$ и $0,45979$\\ \hline \end{табличный} } \конец{таблица}\resizebox, но все они используют\textwidthв качестве основы, что-то вроде:Но с этим кодом таблица масштабируется до 85% ширины текста. Это здорово, за исключением того, что у меня есть несколько таблиц разной ширины, и мне нужно, чтобы все они имели одинаковый размер шрифта, чтобы это не выглядело нелепо. Если бы я использовал приведенный выше код для каждой таблицы, все таблицы стали бы одинаковой ширины, а это означает, что таблицы, которые являются естественными широкими, будут иметь маленький размер шрифта, а таблицы, которые являются естественными узкими, будут иметь огромный размер шрифта.
Есть ли способ использовать
\resizeboxс размером относительно естественного размера таблицы вместо\textwidth?- таблицы
- изменение размера
6
Вы можете использовать
\resizebox{0. 85\width}{} , потому что в этом контексте
\widthотносится к ширинеВ любом случае это не должно содержать подписи, потому что подписи должны иметь одинаковый размер по всему документу. Более того, вы не имеете реального контроля над результатом.
Лучше использовать команду размера шрифта. Возможно действие на
\tabcolsep, на сайте есть несколько примеров.\documentclass{статья} \usepackage{graphicx} \usepackage{siunitx,booktabs,caption} \sisetup{inter-unit-product=\ensuremath{\cdot}} \начать{документ} \begin{таблица}[htbp] \центрирование\размер сноски \caption{Заголовок таблицы} \begin{табличный}{ S[формат таблицы=-3.3] S [формат таблицы = 5.0] S[формат таблицы=-3.3] S [формат таблицы = 1,5] } \toprule {$t_0$ (\si{\мега\эВ\фемто\метр\куб})} & {$t_3$ (\si{\мега\эВ\фемто\метр\до{6}})} & {$v_0/\mu$ (\si{\мега\эВ\фемто\метр})} & {$1/\mu$ (\si{\femto\meter})} \\ \midrule -497,726 и 17270 и -166,924 и 0,45979\\ -497,726 и 17270 и -166,924 и 0,45979\\ -497,726 и 17270 и -166,924 и 0,45979\\ \нижнее правило \end{табличный} \конец{таблица} \конец{документ}Я использовал
siunitxвместо математического режима (что неверно) для единиц измерения, а также для правильного форматирования данных.Вам не нужно изменять размер таблицы, если вы используете
makecell(разрешает разрывы строк в ячейках) иsiunitxдля выравнивания числовых данных. Кроме того, вы получите более профессионально выглядящие таблицы, если будете использовать только горизонтальные линейки скнижных вкладок. `Заголовок загружается для разумного интервала по вертикали для заголовков 92 857 над 92 858 таблицами.\documentclass[12pt,leqno]{статья} \usepackage[utf8]{inputenc} \usepackage[T1]{шрифт} \usepackage{lmodern} \usepackage{siunitx, makecell, caption, booktabs} \DeclareSIUnit \fm {\femto\meter} \начать{документ} \begin{таблица}[!htbp] \центрирование\sisetup{формат таблицы=-3.3} \setcellgapes{6pt}\makegapedcells \caption{Заголовок таблицы} \begin{tabular}{|S|S[table-format=5]|S|S[table-format=1.5]|} \hline & {\ makecell {$ v_0 / \ mu $ \\ (\ si {\ MeV \ cdot \ fm})}} & {\ makecell {$ 1 / \ mu $ \\ (\ si {\ fm})}} \\ \hline -496)}}} & {\ makecell {$ v_0 / \ mu $ \\ (\ si {\ MeV \ cdot \ fm})}} & {\ makecell {$ 1 / \ mu $ \\ (\ si {\ fm })}} \\ \midrule -497,726 и 17270 и -166,924 и 0,45979\ \нижнее правило \end{табличный} \конец{таблица} \конец{документ}4
Если я правильно понимаю проблему, с которой вы столкнулись, дело не в том, что табличный материал слишком широк, а в том, что слишком высок , т.
Если это понимание правильное, изучите, как использовать longtableсреда.Адаптация вашего кода к настройке
longtableпоказана ниже. Он также использует макрос\siиз пакетаsiunitxдля набора научных единиц в соответствии с международно признанными (и обязательными!) стандартами и макросы рисования линий из пакетаbooktabs, чтобы придать таблице «открытый» вид. .Во всяком случае, масштабирования (точнее, уменьшения) всей таблицы только для того, чтобы она поместилась на странице, следует избегать как чумы.
\documentclass{статья} \usepackage{siunitx,booktabs,массив,longtable} \newcolumntype{C}{>{$}c<{$}} % автоматическая версия "c" в математическом режиме \начать{документ} \begin{longtable}{CCCC} %%% определить верхние и нижние колонтитулы \caption{Заголовок таблицы}\label{tab:long}\\ \toprule t_0 & t_3 & v_0/\mu & 1/\mu\\[0.5ex] (\ si {\ мега \ эВ \ фемто \ метр \ куб}) & (\ si {\ мега \ эВ \ фемто \ метр \ до {6}}) & (\ si {\ мега \ эВ \ фемто \ метр}) & (\ si {\ фемто \ метр}) \\ \midrule \endfirsthead %% \multicolumn{4}{l}{(Таблица \ref{tab:long}, продолжение)}\\ \toprule t_0 & t_3 & v_0/\mu & 1/\mu\\[0. 5ex]
(\ si {\ мега \ эВ \ фемто \ метр \ куб}) & (\ si {\ мега \ эВ \ фемто \ метр \ до {6}}) &
(\ si {\ мега \ эВ \ фемто \ метр}) & (\ si {\ фемто \ метр}) \\
\midrule
\endhead
%%
\midrule
\multicolumn{4}{r}{(продолжение на следующей странице)}\\
\endfoot
%%
\нижнее правило
\endlastfoot
%%% тело длинной таблицы
-497,726 и 17270 и -166,924 и 0,45979\\
\end{длинный стол}
\конец{документ}
Как вы уже заметили, изменение размеров таблиц привело к несоответствию шрифтов в документе, что не может заменить хороший дизайн таблиц. К сожалению, ваш пример
табличногоне является минимальнымрабочим документом, но если предположить, что это стандартный классстатьи(поля по умолчанию, размер шрифта и т. д.), таблица занимает менее 85% ширины текста, так что лучшее решение в этом случае ничего не делать (на этот счет только, конечно, никаких левых вертикальных правил, единиц в математическом режиме и т. д.).Если вам действительно нужно изменить естественную ширину таблицы, обратите внимание, что вы можете зафиксировать максимальную ширину несколькими способами, например, используя столбцы
p{}и/или используя средуtable*(обратите внимание на звездочку) или средыtabularxиtabularyсоответствующих пакетов без изменения размера шрифта.В целом, чтобы разместить большой контент на фиксированной ширине таблицы, лучше всего использовать следующие варианты:
- Редизайн стола (может быть лучший вариант).
- Изменить расстояние между столбцами (например,
\tabcolsep). - Разрешить многострочные ячейки (у вас уже есть это с столбцами
p{},tabularxиtabulary, в противном случае используйте\parboxвнутри ячеек.) - В крайнем случае используйте
\smallили даже\foonotesize, но делайте это как можно более последовательно во всем документе. Если этого недостаточно, забудьте об искушении использовать более мелкие шрифты и снова перейдите к 1-му пункту.
Следующий пример с
табличным. Для простоты таблица и пунктирная линия, показывающая максимально допустимую ширину, сделаны с помощью макроса\taby. Обратите внимание, что первая таблица имеет точно такую же ширину, что и при использовании обычной таблицы\tabcolsepвы можете увеличить только до 85% с/без переноса заголовков или уменьшить даже до 70 % без уменьшения шрифта. Только в том случае, если заголовки должны быть одной строкой, при ширине 70% нужен шрифт меньшего размера.\documentclass{статья} \usepackage[utf8]{inputenc} \usepackage[T1]{шрифт} \usepackage{booktabs,table,fp} % просто для примера \parindent0pt\parskip1em % просто от лени \let\Sc\textsuperscript \def\taby#1{% Аргумент - максимальная ширина таблицы \FPeval{\результат}{раунд(#1*100,0)} \ makebox [# 1 \ textwidth] {\ dotfill \ result {} \% \ dotfill} \ par \begin{таблица}{#1\textwidth}{*4{C}} \toprule $t_0$ (МэВ·фм\Sc3) & $t_3$ (МэВ·фм\Sc6) & $v_0/\mu$ (МэВ·фм) & $ 1/\mu$ (fm)\\\midrule $-$497,726 и 17270 & 166,924 и 0.
 sBar». Подробнее см. функцию stat_QC().
sBar». Подробнее см. функцию stat_QC().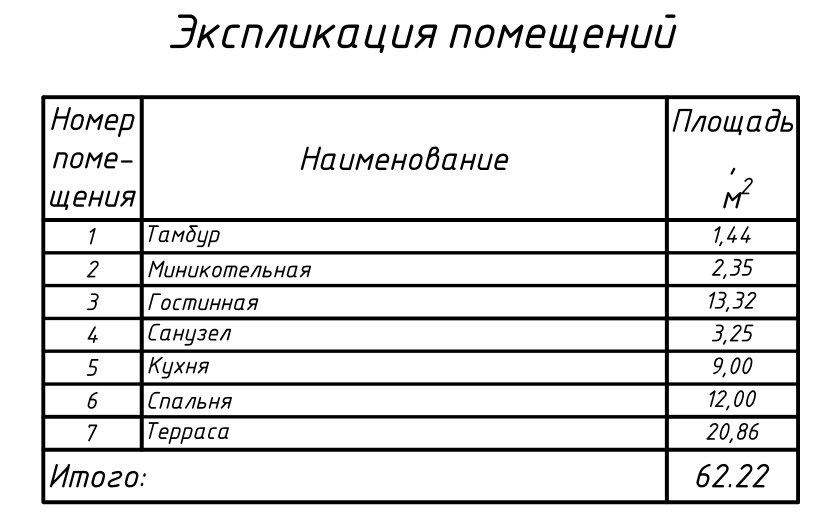 4898
4898

